Ⅰ. Abstract
Large language models (LLMs) based on the generative pre-training transformer (GPT) [44] have demonstrated remarkable effectiveness across a diverse range of downstream tasks. Inspired by the advancements of the GPT, we present PointGPT, a novel approach that extends the concept of GPT to point clouds, addressing the challenges associated with disorder properties, low information density, and task gaps. Specifically, a point cloud auto-regressive generation task is proposed to pre-train transformer models. Our method partitions the input point cloud into multiple point patches and arranges them in an ordered sequence based on their spatial proximity. Then, an extractor-generator based transformer decoder [25], with a dual masking strategy, learns latent representations conditioned on the preceding point patches, aiming to predict the next one in an auto-regressive manner. Our scalable approach allows for learning high-capacity models that generalize well, achieving state-of-the-art performance on various downstream tasks. In particular, our approach achieves classification accuracies of 94.9% on the ModelNet40 dataset and 93.4% on the ScanObjectNN dataset, outperforming all other transformer models. Furthermore, our method also attains new state-of-the-art accuracies on all four few-shot learning benchmarks. Codes are available athttps://github.com/CGuangyan-BIT/PointGPT.
基于GPT预训练的的大型语言模型(LLM)在各种下游任务中表现非常出色。受 GPT 的启发,文章提出了 PointGPT,这是一种将 GPT 概念扩展到点云的新方法,旨在解决无序属性、低信息密度和下游任务差距大的问题。具体来说,文章提出了一种点云自回归生成任务来预训练Transformer。我们的方法将输入点云划分为多个patch,并根据其空间邻近性将它们排列在一个有序序列中。然后使用一个具有双重掩蔽策略的基于extractor-generator模型的Transformer解码器,学习以前面的patch为条件的隐式特征,旨在以自回归的方式预测下一个表示。我们的方法是scalable的而且具有很好的泛化性,在各种下游任务上实现了最先进的性能。特别是在ModelNet40数据集上实现了94.9%的分类准确率,在ScanObjectNN数据集上实现了93.4%的分类准确率,优于所有其他Transformer模型。此外,我们的方法在所有四个小样本学习基准上也达到了新的最先进的准确性。
Ⅱ. Introduction
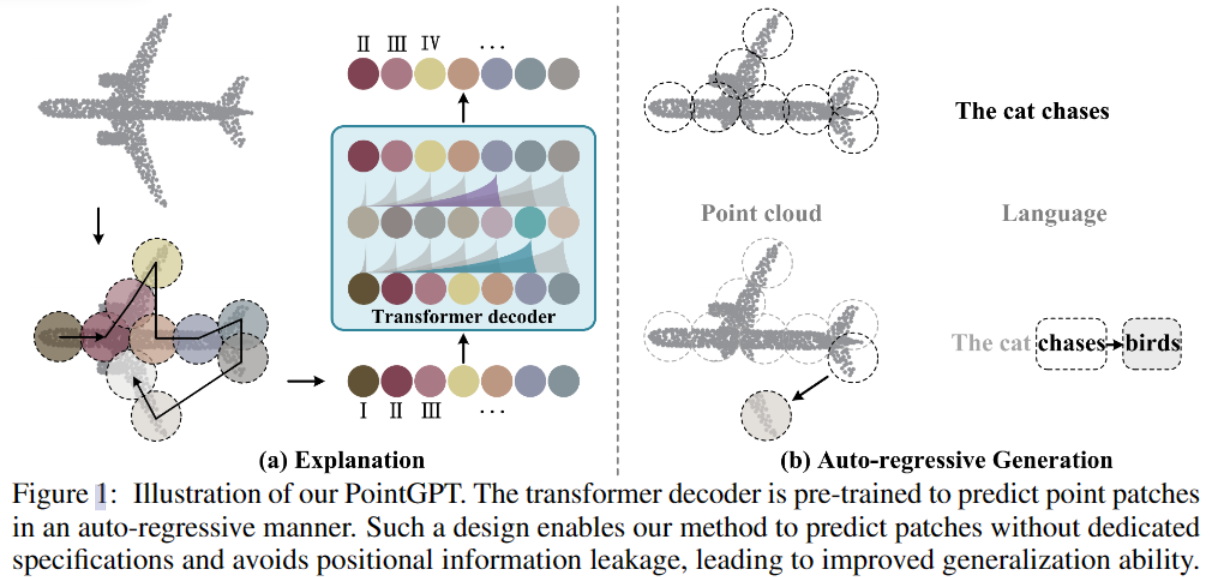
文章发现GPT在学习表征方面特别有效[1],所以引出了一个问题:GPT 能否适用于点云并作为有效的 3D 表示学习器?(can the GPT be adapted to point clouds and serve as an effective 3D representation learner?)但是将GPT应用于点云上面临以下三个问题:
(I) Disorder properties
与句子中单词的顺序排列相比,点云是一种缺乏固有顺序的结构。为了解决这个问题,将patch点块基于几何排序进行排列,即Morton-order曲线[2],它引入了顺序属性并保留局部结构。
(II) Information density differences
语言的信息密度高,因此自动回归预测任务需要高级的语言理解能力。相反,点云是自然信号,具有很高的冗余度,因此即使不进行整体理解也可以完成预测任务。为了解决这种差异,文章提出了一种双重屏蔽策略,该策略为每个token额外屏蔽attending tokens。
(III) Gaps between generation and downstream tasks
尽管具有双重掩蔽策略的模型具有复杂的理解能力,但生成任务主要涉及预测单个点,这可能导致学习到的潜在表征比下游任务具有更低的语义水平。为了解决这一挑战,在Transformer解码器中引入了一个提取器-生成器架构,这样就可以通过生成器促进生成任务,从而提高提取器学习的潜在表示的语义水平。
受我们的PointGPT表现出的良好性能的启发,我们努力研究它的scaling,并进一步推动它的性能极限。然而,与NLP和图像相比,由于现有公共点云数据集的规模有限。这种数据集大小的差异带来了潜在的过拟合问题。为了缓解这一问题并充分释放PointGPT的力量,文章通过混合各种点云数据集(如ShapeNet和S3DIS)来收集更大的预训练数据集。此外,引入了后续的后预训练阶段(post-pre-training stage),该阶段涉及对收集的标记数据集执行监督学习,使PointGPT能够整合来自多个来源的语义信息。在这个框架内,我们的scaled模型在各种下游任务上实现了最先进的(SOTA)性能。在对象分类任务中,我们的PointGPT在ModelNet40数据集上达到94.9%的准确率,在ScanObjectNN数据集上达到93.4%的准确率,优于所有其他变压器模型。在少量的学习任务中,我们的方法在所有四个基准上也达到了新的SOTA性能。
Contributions:
-
针对点云自监督学习,提出了一种新的GPT方案PointGPT。PointGPT利用点云自动回归生成任务,同时减少位置信息泄漏,优于其他单模态自监督方法。
-
提出了一种双掩蔽策略来创建有效的生成任务,并引入了一种提取-生成器Transformer架构来提高学习表征的语义水平。这些设计提高了pointGPT在下游任务上的性能。
-
引入后预训练阶段,收集更大的数据集,以方便高容量模型的训练。使用PointGPT,我们的缩放模型在各种下游任务上实现SOTA性能。
Ⅲ. Methodology
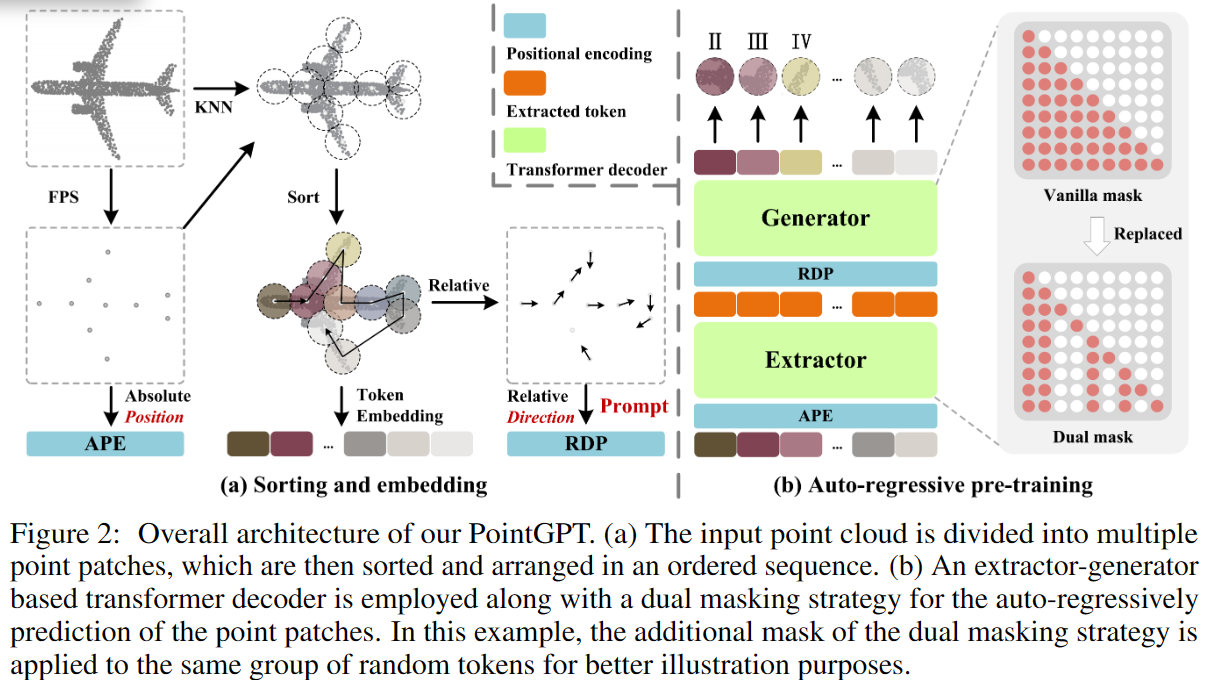
给定一个点云 $ X={x_1,x_2,…,x_M}\subseteq\mathbb{R}^3 $ ,预训练过程中PointGPT的整体流程如图2所示。通过将点云分为多个patch并使用Morton排序构建有序序列,然后将结果序列输入提取器以学习潜在表示,生成器以自回归的方式预测随后的点补丁。在预训练之后,生成器不再使用,并且提取器将在不使用双重屏蔽策略的情况下,利用学习到的潜在表征进行下游任务。
3.1 Point Cloud Sequencer
GPT方法在自然语言处理中成功,但点云领域由于无序稀疏结构挑战。通过点补丁划分、排序和嵌入三阶段,实现有序点云序列,捕获几何信息。
点Patch分区
考虑到点云的固有稀疏性和无序性,输入点云通过最远点采样(FPS)和K最近邻(KNN)算法进行处理,以获取中心点和点补丁。给定具有M个点的点云X,我们首先使用FPS采样n个中心点C。然后,利用KNN算法从X中为每个中心点选择k个最近点,构建n个点补丁P。总之,划分过程可以表示为:
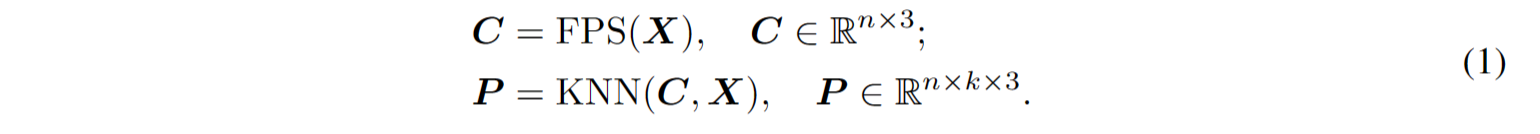
Patch排序
为了解决点云固有的无序特性,获得的点补丁根据它们的中心点被组织成一个连贯的序列。具体而言,中心点的坐标使用Morton编码[2]编码为一维空间,然后进行排序以确定这些中心点的顺序 $\mathcal{O}$ 。然后按照相同的顺序排列点补丁。排序后的中心点 $C^3$ 和排序后的点补丁 $P^s$ 的获取过程如下:
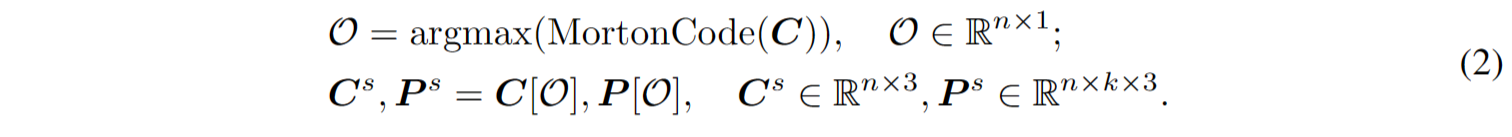
Embedding
在Point-MAE [3]的基础上,采用PointNet网络提取每个点补丁的丰富几何信息。为促进训练的收敛性,相对于其中心点,利用每个点的归一化坐标。具体而言,将排序后的点补丁$P^3$嵌入到D维令牌 T 中,过程如下:
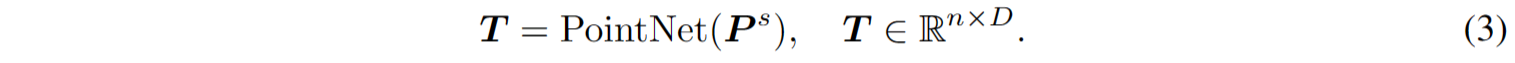
3.2 Transformer Decoder with a Dual Masking Strategy
将GPT [4] 直接扩展到点云的方法是利用原始Transformer解码器自回归预测点补丁,然后对所有预训练参数进行微调以用于下游任务。然而,由于点云信息密度有限和生成任务与下游任务之间存在差距,该方法受到低级语义的影响(生成任务只能捕获低级语义信息)。为解决这个问题,提出了双重掩码策略以促进对点云的全面理解。此外,文章还引入了一个提取器-生成器Transformer架构,其中生成器更专注于生成任务,并在预训练后被丢弃;通过引入生成器提高了提取器学到的潜在表示的语义水平。
双掩蔽策略
Transformer解码器中的原始掩码策略使得每个令牌能够接收来自所有前面点令牌的信息。为了进一步促使学习有用的表示,提出了双重掩码策略,在预训练期间除了原本的掩码外,还对每个令牌的一部分前导令牌进行额外的掩码。生成的双重掩码 $M^d$ 如图2(b)所示,带有双重掩码策略的自注意过程可以表示为:
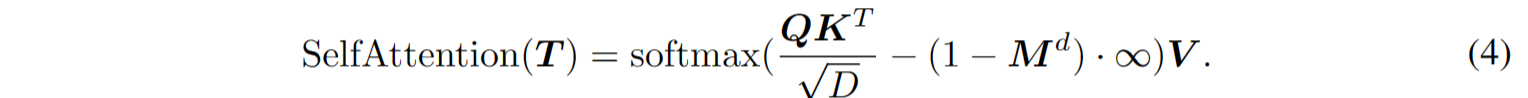
其中,$Q、K、V$分别是使用不同权重对D通道编码的 T 。在$M^d$中,被掩码的位置设为0,未被掩码的位置设为1。
提取器与生成器
提取器完全由采用双重掩码策略Transformer解码器块组成,首先通过提取器得到潜在表示T,其中每个点token只与未被掩码的前导token关联。考虑到点patch以归一化坐标表示,点云的全局结构对点云理解至关重要,因此使用正弦位置编码[5](PE)将排序后的中心点 $C^s$ 的坐标映射到绝对位置编码(APE)。位置编码添加到每个Transformer块,提供位置信息并融入全局结构信息。生成器架构与提取器相似但包含较少的Transformer块。它以提取的令牌 $\mathcal{T}$ 作为输入,生成点token $T^g$ 用于后续预测。然而,patch的顺序可能会受到中心点采样过程的影响,并在预测后续补丁时引起歧义。这妨碍了模型有效学习有意义的点云表示。为解决这个问题,在生成器中提供了相对于后续点补丁的方向作为提示,而不会揭示被掩码补丁的位置和点云的整体对象形状。相对方向提示RDP的制定如下:
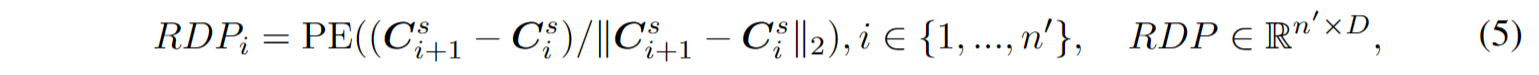
式中n ‘ = n−1。综上所述,提取器-生成器体系结构中的程序表述为:
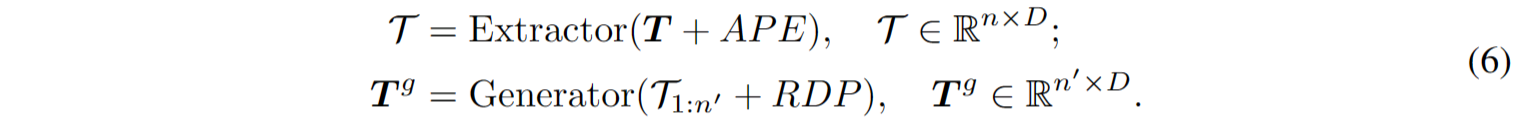
预测头
利用预测头预测坐标空间中后续的点块。它由两个完全连接(FC)层和整流线性单元(ReLU)激活的双层MLP组成。预测头将标记 $T^g$ 投影到向量上,其中输出通道的数量等于patch中坐标的总数。然后,对这些向量进行重构,构造预测点patch $P^{pd}$ :
3.3 Generation Target
每个点块的生成目标是预测随后点块内点的坐标。鉴于预测的点块 $P^{pd}$,以及对应于排序后的点块 $P^s$ 中最后 n′ 个点块的地面真实点块 $P^{gt}$,生成损失 $\mathcal{L}^g$ 使用 Chamfer 距离(CD) 的 L1 形式和 L2 形式进行构建,分别表示为 $\mathcal{L}^g_1$ 和 $\mathcal{L}^g_2$。具体而言,生成损失计算为 $L^g = L^g_1 + L^g_2$。其中,ln 形式的 CD 损失 $\mathcal{L}^g_n$,其中 n ∈ {1, 2},定义如下:
| 其中 | P | 是集合 P 的基数,$∥a−b∥_n$ 表示a和b之间的 $\mathcal{L}_n$ 距离。 |
此外,我们还发现将生成任务作为辅助目标整合到微调过程中可以加速训练收敛并提高监督模型的泛化能力。这种方法在下游任务上实现了更强大的性能,与 GPT [4] 的理念一致。具体而言,在微调阶段,我们优化以下目标:$\mathcal{L}^f = \mathcal{L}^d + λ × \mathcal{L}^g$,其中 $\mathcal{L}^d$ 代表下游任务的损失, $\mathcal{L}^g$ 代表先前定义的生成损失,参数 λ 平衡了每个损失项的贡献。
3.4 Post-Pre-training
目前的点云自监督学习方法直接在目标数据集上微调预训练模型,由于有限的语义监督信息,这可能导致潜在的过拟合。为了缓解这个问题并促进高容量模型的训练,我们采用中间微调策略 [6] 并为 PointGPT 引入一个后预训练阶段。在这个阶段,利用一个带标签的混合数据集(Sec. 4.1),该数据集收集并对齐了多个带标签的点云数据集。通过在该数据集上进行监督训练,有效地从多样化的来源中整合了语义信息。随后,在目标数据集上进行微调,将学到的通用语义知识转移到任务特定的知识。
Ⅳ. Experiments
4.1 Setups
PointGPT采用ViT-S配置进行训练,称为PointGPT-S。此外,通过将提取器扩展到ViT-B和ViT-L配置,得到PointGPT-B和PointGPT-L,研究高容量模型。
PointGPT-S在ShapeNet数据集上进行自监督预训练,为与baseline方法保持一致不进行后预训练阶段。ShapeNet包含55个对象类别的50,000多个唯一3D模型。为支持高容量PointGPT模型的训练,收集了两个数据集(用于PointGPT-B和PointGPT-L):(I)无标签混合数据集(UHD)用于自监督预训练,汇集来自各种数据集的点云;(II)带标签混合数据集(LHD)用于监督后预训练,对齐不同数据集的标签语义。
输入点云从原始点云中采样1024点,然后将每个点云分成64个点块,每个块包含32个点。使用AdamW优化器进行300个epoch的PointGPT模型预训练,批量大小为128,初始学习率为0.001,权重衰减为0.05。采用余弦学习率衰减[28]。
4.2 Downstream Tasks
Object classification on ScanObjectNN & ModelNet40 dataset: 其中ScanObjectNN是真实世界数据集,ModelNet40是合成数据集。
Few-shot learning: 在没有后预训练阶段的ModelNet40数据集上进行了少镜头学习实验,w ∈ {5, 10} 表示随机选择的类的数量,s ∈ {10, 20} 表示每个选定类的随机采样对象的数量。
Part segmentation: 在ShapeNetPart[62]数据集上进行了评估。
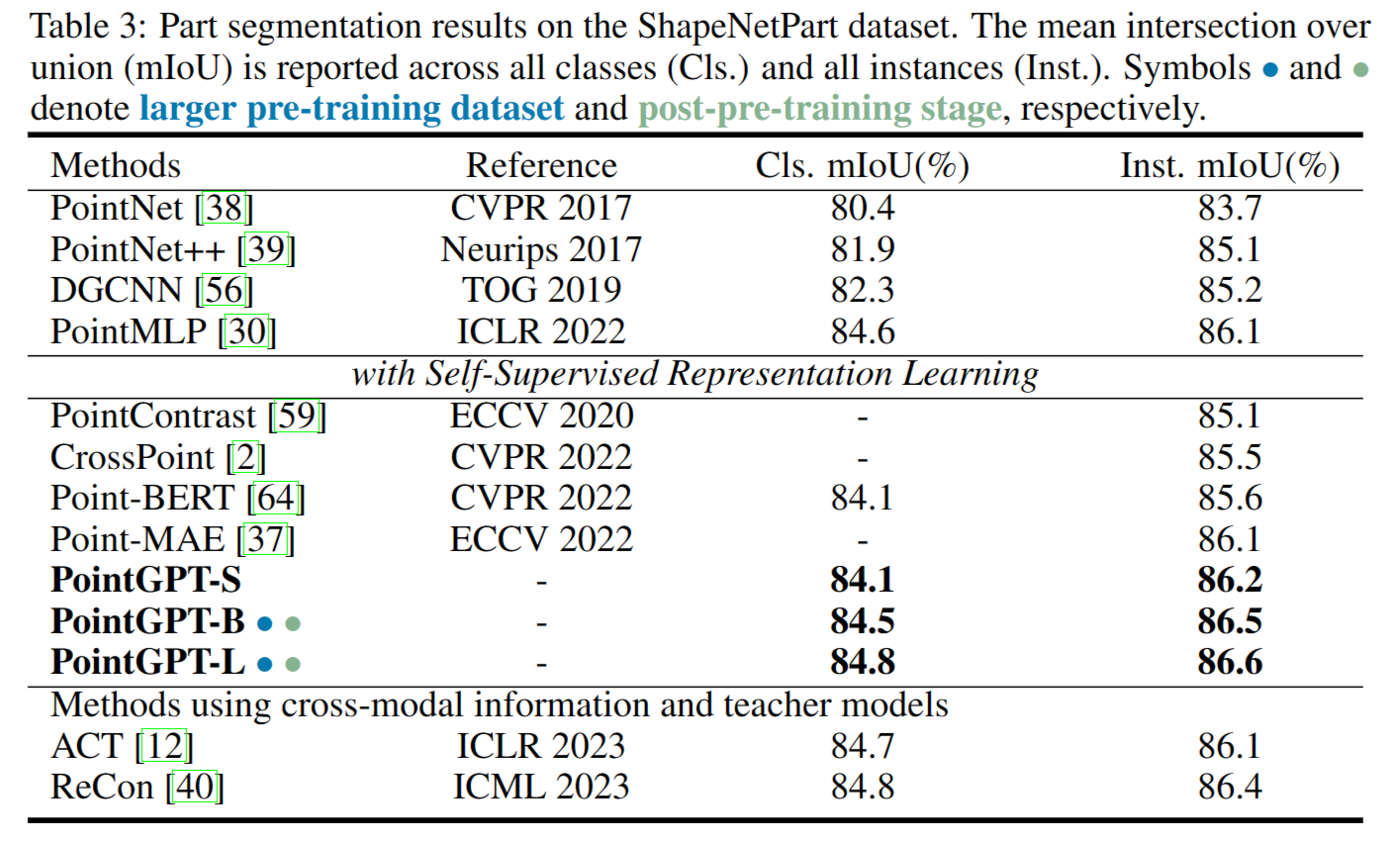
4.3 Ablation Studies
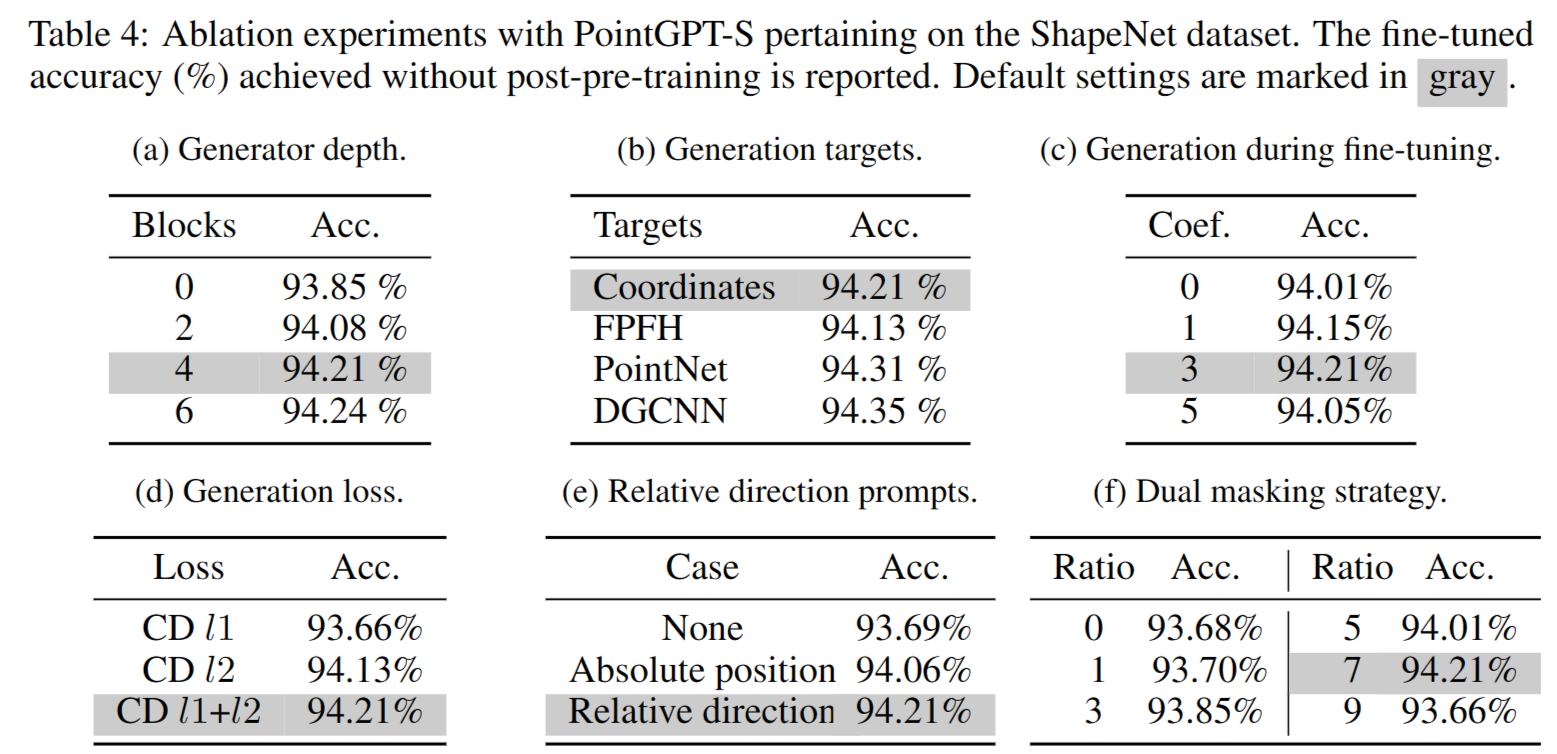
生成器:表4(a)研究了改变生成器深度的效果。结果表明,提取器-生成器架构有助于学习强有力的语义表示,特别是与深度生成器结合时,整体性能得到改善。然而,由于深度生成器带来的计算复杂性,选择将生成器的深度设置为4作为默认设置。
生成目标: 生成目标对于模型学习给定数据的内在特征至关重要。表 4(b) 展示了四种不同的生成目标,可将其分为两类:可直接获取的一阶段目标,包括点坐标和 FPFH [7] ;以及由训练有素的深度网络提取的二阶段目标,包括 PointNet 和 DGCNN。实验结果表明,使用手工制作的 FPFH 特征会导致性能不佳,这可能归因于低级几何特征的过度拟合。采用两阶段目标的变体优于采用点坐标目标的变体。然而,教师模型的预训练和推理过程不可避免地会产生额外的计算成本。
微调阶段的生成任务:在微调阶段将生成任务作为辅助目标加入。表4(c)呈现了在微调损失中改变生成损失系数λ时获得的结果。结果表明,这个辅助目标充当正则化项,提高了监督模型的泛化能力。此外,结果表明随着系数的增加,在分类任务中达到的准确度呈现先增加后减小的趋势,在λ = 3时达到最高值。
生成损失:表4(d)展示了使用不同生成损失函数的变体的性能,包括l1形式的CD损失、l2形式的CD损失以及l1和l2形式的CD损失的组合。结果表明,l1和l2形式的组合实现了更优越的性能。我们分析认为l2形式更有效地引导网络向收敛方向发展,而l1形式具有更好的稀疏性,因此两者的组合更为有效。
相对方向提示:表4(e)分析了利用相对方向提示的效果。利用相对方向提示的变体优于使用绝对位置编码和不包括位置编码的变体。我们假设这种改进源于相对方向提示防止模型对块的顺序过拟合的能力,从而增强了PointGPT在下游任务中的性能。
双重掩码策略:我们对双重掩码策略的影响进行了分析,并在表4(f)中寻找合适的掩码比例。将掩码比例减少到0相当于使用普通的掩码策略。结果表明,过高和过低的掩码比例都导致性能下降。实验结果表明,双重掩码策略有效促进了有益的表示学习,并增强了预训练模型的泛化能力。
Ⅴ. Conclusion
In this paper, we present PointGPT, a novel approach that extends the GPT concept to point clouds, addressing the challenges associated with disorder properties, information density differences, and gaps between the generation and downstream tasks. Unlike recently proposed self-supervised masked point modeling approaches, our method avoids overall object shape leakage, attaining improved generalization ability. Additionally, we explore a high-capacity model training process and collect hybrid datasets for pre-training and post-pre-training. The effectiveness and strong generalization capabilities of our approach are verified on various tasks, indicating that our PointGPT outperforms other single-modal methods with similar model capacities. Furthermore, our scaled models achieve SOTA performance on various downstream tasks, without the need for cross-modal information and teacher models. Despite the promising performance exhibited by PointGPT, the data and model scales explored for PointGPT remain several orders of magnitude smaller than those in NLP and image processing domains. Our aspiration is that our research can stimulate further exploration in this direction and narrow the gaps between point clouds and these domains.
本文提出了PointGPT,一种将GPT概念扩展到点云的新方法,解决了与无序属性、信息密度差异和生成与下游任务之间的差距相关的挑战。与最近提出的自监督遮蔽点建模方法不同,我们的方法避免了整体对象形状泄漏,达到了更好的泛化能力。此外,我们探讨了高容量模型训练过程,并收集了用于预训练和后预训练的混合数据集。我们的方法在各种任务上验证了其有效性和强大的泛化能力,表明PointGPT在具有相似模型容量的其他单模态方法之上表现更佳。此外,我们的扩展模型在各种下游任务上实现了最先进的性能,无需跨模态信息和教师模型。尽管PointGPT展现出令人期待的性能,但其数据和模型规模仍然比NLP和图像处理领域小数个数量级。我们希望我们的研究能够激发在这个方向上的进一步探索,并缩小点云与这些领域之间的差距。
References
[1] Chen, M., Radford, A., Child, R., Wu, J., Jun, H., Luan, D., & Sutskever, I. (2020). Generative Pretraining From Pixels. International Conference on Machine Learning,International Conference on Machine Learning.
[2] Morton, G. M. . (1966). A Computer Oriented Geodetic Data Base and a New Technique in File Sequencing.
[3] Pang, Y., Wang, W., Tay, F., Liu, W., Tian, Y., & Yuan, L. (n.d.). Masked Autoencoders for Point Cloud Self-supervised Learning.
[4] Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (n.d.). Improving Language Understanding by Generative Pre-Training.
[5] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, AidanN., … Polosukhin, I. (2017). Attention is All you Need. Neural Information Processing Systems,Neural Information Processing Systems.
[6] Wang, L., Huang, B., Zhao, Z., Tong, Z., He, Y., Wang, Y., … & Qiao, Y. (2023). Videomae v2: Scaling video masked autoencoders with dual masking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 14549-14560).
[7] Rusu, R. B., Blodow, N., & Beetz, M. (2009, May). Fast point feature histograms (FPFH) for 3D registration. In 2009 IEEE international conference on robotics and automation (pp. 3212-3217). IEEE.