Ⅰ. Abstract
In contrast to numerous NLP and 2D computer vision foundational models, the learning of a robust and highly generalized 3D foundational model poses considerably greater challenges. This is primarily due to the inherent data variability and the diversity of downstream tasks. In this paper, we introduce a comprehensive 3D pre-training framework designed to facilitate the acquisition of efficient 3D representations, thereby establishing a pathway to 3D foundational models. Motivated by the fact that informative 3D features should be able to encode rich geometry and appearance cues that can be utilized to render realistic images, we propose a novel universal paradigm to learn point cloud representations by differentiable neural rendering, serving as a bridge between 3D and 2D worlds. We train a point cloud encoder within a devised volumetric neural renderer by comparing the rendered images with the real images. Notably, our approach demonstrates the seamless integration of the learned 3D encoder into diverse downstream tasks. These tasks encompass not only high-level challenges such as 3D detection and segmentation but also low-level objectives like 3D reconstruction and image synthesis, spanning both indoor and outdoor scenarios. Besides, we also illustrate the capability of pre-training a 2D backbone using the proposed universal methodology, surpassing conventional pre-training methods by a large margin. For the first time, PonderV2 achieves state-of-the-art performance on 11 indoor and outdoor benchmarks. The consistent improvements in various settings imply the effectiveness of the proposed method. Code and models will be made available at https://github.com/OpenGVLab/PonderV2.
与许多 NLP 和 2D 计算机视觉基础模型相比,稳健且高度概括的 3D 基础模型的学习带来了更大的挑战。这主要是由于固有的数据可变性和下游任务的多样性。
在本文中,我们介绍了一个全面的 3D 预训练框架,旨在促进获得有效的 3D 表示,从而为 3D 基础模型建立途径。受 信息丰富的 3D 特征应该能够编码可用于渲染真实图像的丰富几何和外观线索 这一事实的启发,我们提出了一种新颖的通用范式,通过可微分神经渲染(NERF)来学习点云表示,作为 3D 和 2D 世界之间的桥梁。我们通过将渲染图像与真实图像进行比较,在设计的体积神经渲染器中训练点云编码器。值得注意的是,我们的方法展示了学习到的 3D 编码器无缝集成到不同的下游任务中。这些任务不仅包括 3D 检测和分割等高级挑战,还包括跨越室内和室外场景的 3D 重建和图像合成等低级目标。此外,我们还说明了使用所提出的通用方法预训练 2D 主干的能力,大大超过了传统的预训练方法。第一次,PonderV2 在 11 个室内和室外基准测试中实现了最先进的性能。各种设置的一致改进意味着所提出方法的有效性。
Ⅱ. Contributions
我们的方法虽然非常简单且易于实现,但证明了其健壮的性能。为了验证其能力,我们在超过9个室内和室外任务中进行了一系列广泛的实验,包括室内/室外分割和检测等高级任务,以及图像合成和室内场景/对象重建等低级任务。我们在超过11个室内/室外基准测试中达到最先进的性能。PonderV2的部分验证集性能与基线和具有相同主干的最先进方法的比较如图1所示。充分和令人信服的结果表明所提出的普遍方法的有效性。具体来说,我们首先在各种流行的室内基准测试中以多帧RGB-D图像作为输入,在不同的主干网上评估了PonderV2,证明了它的灵活性。此外,我们为各种下游任务预训练了单个主干,即SparseUNet,它以整个场景点云作为输入,并且在各种室内3D基准测试中显著优于具有相同主干的最先进方法。例如,PonderV2在ScanNet语义分割基准上达到77.0 valmIoU,在ScanNet基准上以78.5的测试mIoU排名第一。PonderV2在ScanNet200语义分割基准测试中也以34.6的mIoU排名第一。最后,我们在室外自动驾驶场景中进行了大量的实验,也达到了SOTA的验证性能。例如,我们在nuScenes验证集上实现了3D检测73.2 NDS和3D分割79.4 mIoU,分别比基线高3.0和6.1。结果显示PonderV2的有效性。
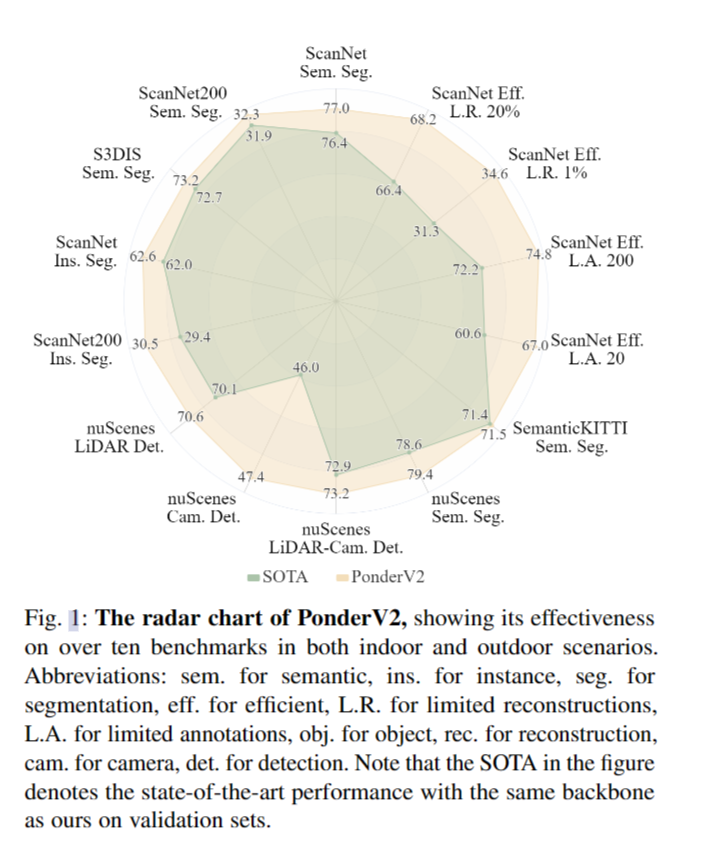
-
我们建议利用可微神经渲染作为一种新的通用预训练范例,为3D视觉领域量身定制。这个范例被命名为PonderV2,它捕捉了3D物理世界和2D感知画布之间的自然关系。
-
我们的方法擅长于获取有效的3D表示,能够通过利用神经渲染编码复杂的几何和视觉线索。这个通用的框架扩展了它的适用性范围的模式,包括3D和2D领域,包括但不限于点云和多视图图像。assets
-
所提出的方法在许多流行的室内和室外基准上达到了最先进的性能,并且可以灵活地集成到各种主干网中。除了高级感知任务,PonderV2还可以增强低级任务,如图像合成、场景和物体重建等。PonderV2的有效性和灵活性展示了为3D基础模型铺平道路的潜力。
Ⅲ. Methodology
3.1 Universal Pipeline Overview
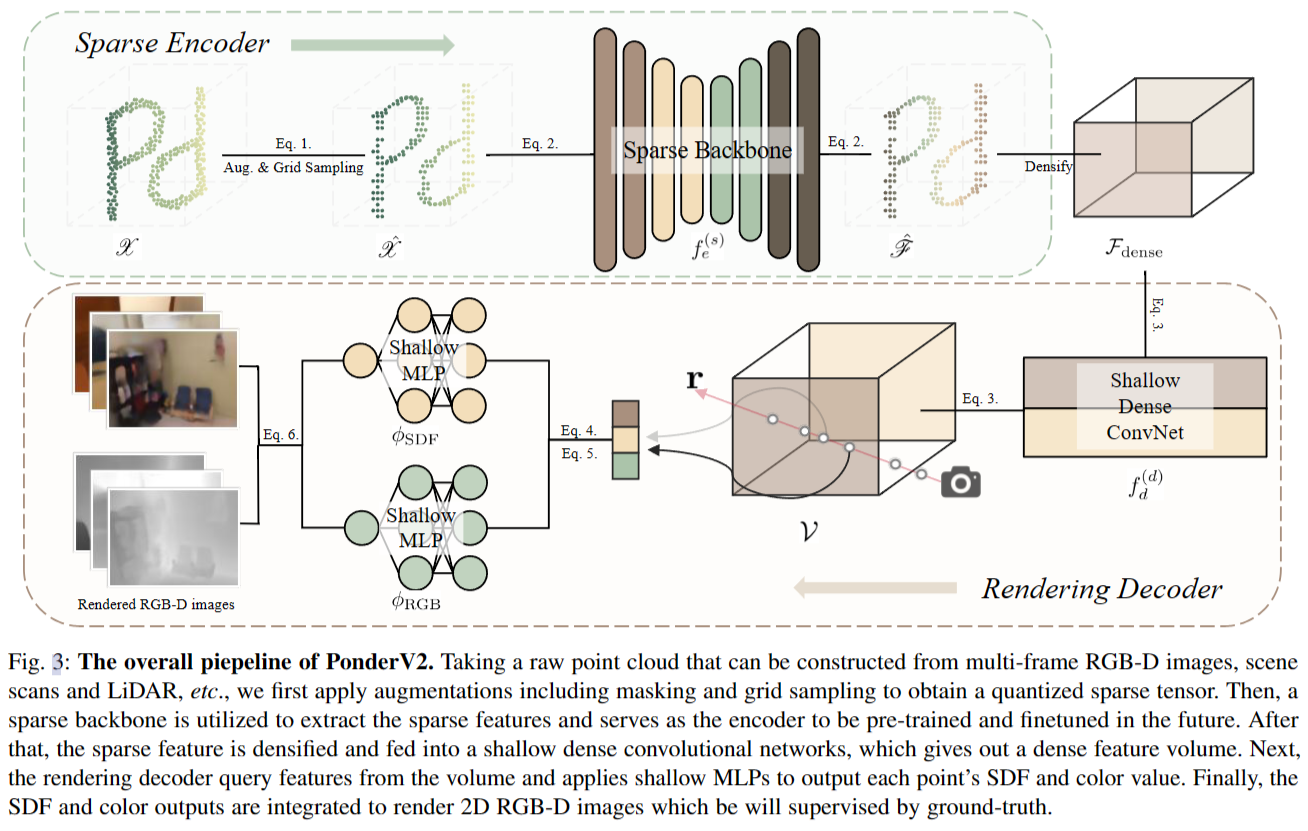
如图3所示,我们的管道的输入是原始的稀疏点云$X = {Cin, Fin}$,由一组n个坐标$Cin∈R^{n×3}$ 及其对应的下巴通道特征 $Fin∈Rn×chin$ 组成,可能包括颜色或强度等属性。这些点云可以从各种来源生成,包括RGB-D图像、扫描或激光雷达数据。在深入研究我们的主干之前,我们首先对输入数据应用增强,并使用特定的网格大小 $g = [gx, gy , gz ] ∈ R3$ 对其进行量化。这个过程可以表示为 \(X^` = G(T (X ), g)) = { ˆCin, ˆFin}\quad(1)\) 其中 $G(·, g) $是一个网格采样函数,旨在确保每个网格只有一个点采样。$T (·) $表示增强变换函数$X^`$ 是采样点。
然后,我们将 X 输入稀疏主干$f ^{(s)}e (·)$,作为我们的预训练编码器。输出通过以下方式获得 \(F = f ^{(s)}_e (X^`) = { ˆCout, ˆFout},\quad(2)\) 其中 $ˆCout $和 $ˆFout $分别是稀疏输出的坐标和特征。为了使稀疏特征与我们基于体积的解码器兼容,我们通过致密化过程将它们编码为体积表示。具体来说,我们首先以 $lx × ly × lz$ 体素网格的分辨率离散化 3D 空间。随后,通过基于相应稀疏坐标应用平均池化来聚合属于同一体素的稀疏特征。聚合将导致密集体积特征 $Fdense ∈ R^{lx×ly ×lz ×chout}$ ,其中空体素网格用零填充。然后应用浅层密集卷积网络$f^{(d)}_d(·) $得到增强的3D特征体积$V∈R^{lx ×ly ×lz ×chvol}$,可表示为 \(V = f^{(d)}_d(F_{dense})\quad(3)\) 在密集三维体$V$的情况下,我们提出了一种新颖的可微体绘制方法来重建投影的彩色图像和深度图像作为pretext任务。受到 NeuS 的启发,我们将场景表示为隐式符号距离函数(SDF)字段,以便能够表示高质量的几何细节。具体来说,给定相机姿态 P 和采样像素 x ,我们从相机的投影中心向像素方向 d 发射射线 r。沿着每条射线,我们采样 D 个点 ${p_j = o + t_j · d | j = 1, …, D ∧ 0 ≤ t_j < t_j+1}$ , 其中$t_j$为每个点到相机中心的距离,通过三线插值从V中查询每个点的三维特征$f_j$。使用浅层MLP $φSDF$预测每个点$p_j$的SDF值$s_j$ \(s_j = φSDF(p_j, f_j)\quad(4)\) 为了确定颜色值,我们的方法从 NeuS 中获得灵感,并将表面法线$n_j$上的颜色场(即光线点$p_j$处SDF值的梯度)与由$φSDF$导出的几何特征向量$h_i$结合在一起。这可以产生一个颜色表示 \(c_j = φRGB(p_j , f_j , d_i, n_j , h_j ),\quad(5)\) 其中$φRGB$由另一个浅MLP参数化。随后,我们通过对预测颜色和沿射线 r 的采样深度进行积分,使用以下方程绘制2D颜色$C(r)$和深度$D(r)$ \(\hat{C}(\mathbf{r})=\sum_{j=1}^{D}w_jc_j,\quad\hat{D}(\mathbf{r})=\sum_{j=1}^{D}w_jt_j,\quad(6)\) 这些方程中的权重wj是一个无偏的、闭塞感知的因子,如 NeuS 所示,计算为wj = Tj αj。式中,$T{j}=\prod_{k=1}^{j-1}(1-\alpha_{k})$ 为累积透过率,αj为不透明度值,计算公式为 \(\alpha_j=\max\biggl(\frac{\sigma_s(s_j)-\sigma_s(s_{j+1})}{\sigma_s(s_j)},0\biggr),\quad(7)\) 其中 $σs(x) = (1 + e^{−sx})^{−1}$ 是由可学习参数 s 调制的Sigmoid函数。
最后,我们的优化目标是通过$λ_C$和$λ_d$因子调节颜色和深度之间的权重,使渲染的2D像素空间$L^1$重构损失最小化,即 \(\mathcal{L}=\frac{1}{|\mathbf{r}|}\sum_{\mathbf{r}\in\mathbf{r}}\lambda_C\cdot\|\hat{C}(\mathbf{r})-C(\mathbf{r})\|+\lambda_D\cdot\|\hat{D}(\mathbf{r})-D(\mathbf{r})\|\quad(8)\)
3.2 Indoor Scenario
虽然提出的基于呈现的pretext任务以完全无监督的方式运行,但该框架可以很容易地扩展到监督学习,通过合并现成的标签来进一步改进学习表征。由于室内场景有大量的合成数据和可用的注释,渲染解码器还可以在2D中渲染语义标签。具体来说,我们使用了一个额外的浅MLP,表示为$\phi_{semantic}$,来预测每个查询点的语义特征 \(\mathrm{l}_{j}=\phi_{\mathrm{SEMANTIC}}(\mathbf{p}_{j},\mathbf{f}_{j},\mathbf{n}_{j},\mathbf{h}_{j}),\quad(9)\) 这些语义特征可以使用类似于Eq. 6所描述的加权方案投射到2D画布上。为了进行监督,我们利用了每个像素文本标签的CLIP[Learning Transferable Visual Models From Natural Language Supervision]特征,这是大多数室内数据集中易于获得的属性。
值得注意的是,当处理大量未标记的RGB-D数据时,语义渲染也可以通过利用现有的2D分割模型切换到无监督的方式。例如,利用Segment-Anything[8]或diffusion[77]特征来提供伪语义特征作为监督的替代方法,也可以将知识从2D基础模型提取到3D主干。这方面的进一步研究有待于未来的工作,因为本文的主要重点是新的预训练方法本身。
3.3 Outdoor Scenario
为了进一步展示我们的预训练范式的泛化能力,我们还将我们的方法应用于户外场景,其中通常可以使用多视图图像和LiDAR点云。为了使预训练方法适用于这些输入,我们将它们转换为三维体积空间。
具体来说,对于LiDAR点云,我们遵循3.1节中相同的过程来增强点云,并对3D骨干提取的点特征进行体素化。
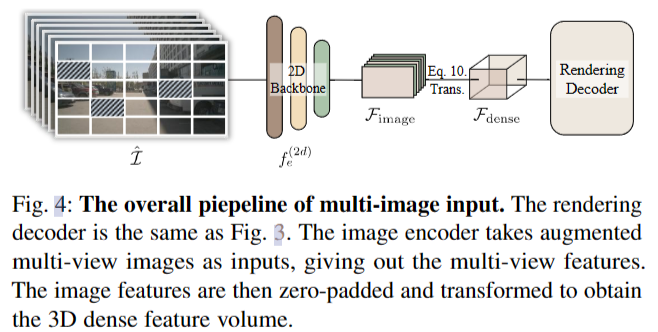
对于多视图图像 $I = {I1, I2,…}$ ,受MAE的启发,我们首先掩膜部分像素作为数据增强,得到I。然后,我们利用二维主干$f^{(2D)}e$提取多视图图像特征$F{image} = f^{(2D)}e (I)$。然后将二维特征转换为3D ego-car坐标系,得到三维密集体特征。具体来说,我们首先预先定义三维体素坐标$X_p∈N^{lx ×ly ×lz ×3}$,然后投影Xp多视图图像来索引相应的二维特征。过程可以通过以下方式计算 \(\mathcal{F}_{\mathrm{dense}}=\mathcal{B}(T_{\mathrm{c}2\mathrm{i}}T_{\mathrm{l}2\mathrm{c}}X_{p},\mathcal{F}_{\mathrm{image}}),\quad\quad(10)\) 式中,$T{l2c}$和$T_{c2i}$分别表示LiDAR坐标系到相机坐标系和相机坐标系到图像坐标系的变换矩阵,$\mathcal{B}$ 表示双线性插值。多视图图像情况的编码过程如图4所示。
Ⅳ. Experiment
4.1 Indoor Multi-frame RGB-Ds as Inputs
我们首先在室内数据集上进行综合实验,主要包括两部分。在第一部分中,我们使用轻量级主干进行烧蚀研究,该主干仅将多帧RGB-D作为输入。我们称这种变体为Ponder-rgbd。接下来的部分主要关注一个单一的、统一的预训练模型,该模型将性能推向极限,大大超越了以前的SOTA预训练方法。
我们使用ScanNet [78] RGB-D图像作为我们的预训练数据集。ScanNet是一个广泛使用的真实世界室内数据集,包含超过1500个室内场景。每个场景都由RGB-D相机仔细扫描,总共产生约250万帧RGB-D帧。我们遵循与VoteNet相同的train / val分割[79]。在这一部分中,我们还没有介绍语义渲染,它将在场景级部分作为输入使用。
Object Detection
Omitted
Semantic Segmentation
Omitted
Scene Reconstruction
Omitted
Image Synthesis From Point Clouds
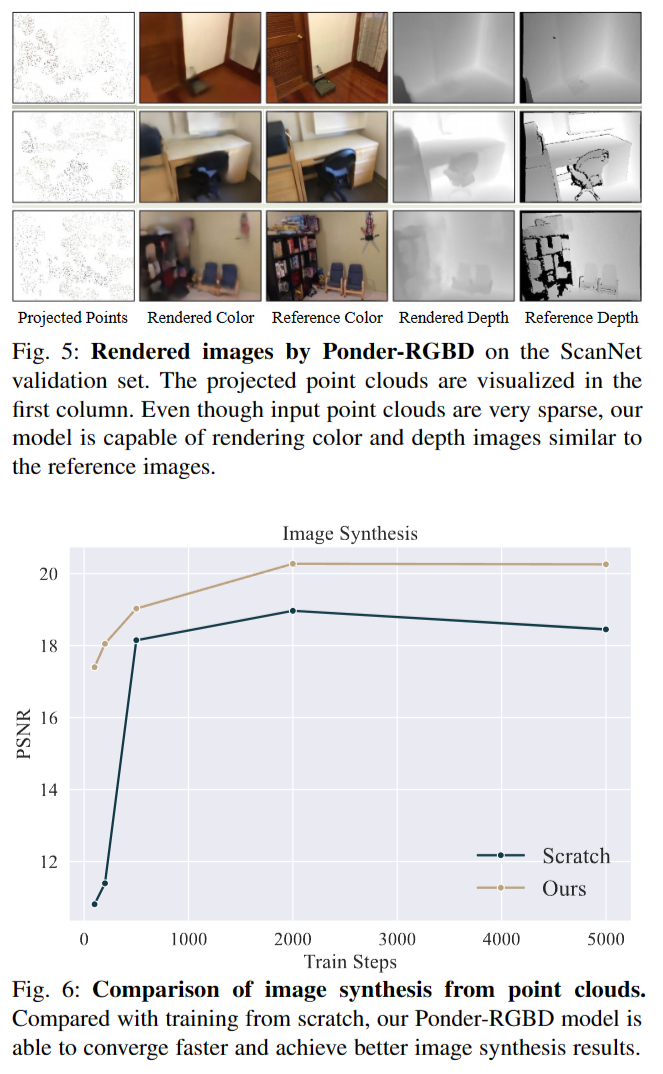
我们还验证了我们的方法在另一个低级任务的有效性,即从点云合成图像。我们使用Point-NeRF[75]作为基线。point - nerf使用带有相关神经特征的神经3D点云来渲染图像。它既可以用于各种场景的通用设置,也可以用于单个场景的拟合设置。在我们的实验中,我们主要关注Point-NeRF的可泛化设置。我们将point - nerf的二维图像特征替换为DGCNN网络提取的点特征。按照PointNeRF的相同设置,我们使用DTU[94]作为评估数据集。DTU数据集是一个包含80个场景的多视图立体数据集,具有成对的图像和相机姿势。我们将DGCNN编码器和颜色解码器作为Point-NeRF的权重初始化。我们使用PSNR作为评价合成图像质量的指标。
结果如图6所示。通过利用我们方法的预训练权值,图像合成模型能够以更少的训练步骤更快地收敛,并且比从头开始训练获得更好的最终图像质量。Ponder-RGBD渲染的彩色图像和深度图像如图5所示。如图所示,尽管输入点云非常稀疏,但我们的方法仍然能够绘制出与参考图像相似的颜色和深度图像。
Ablation Study
Omitted
4.2 Indoor Scene Point Clouds as Inputs
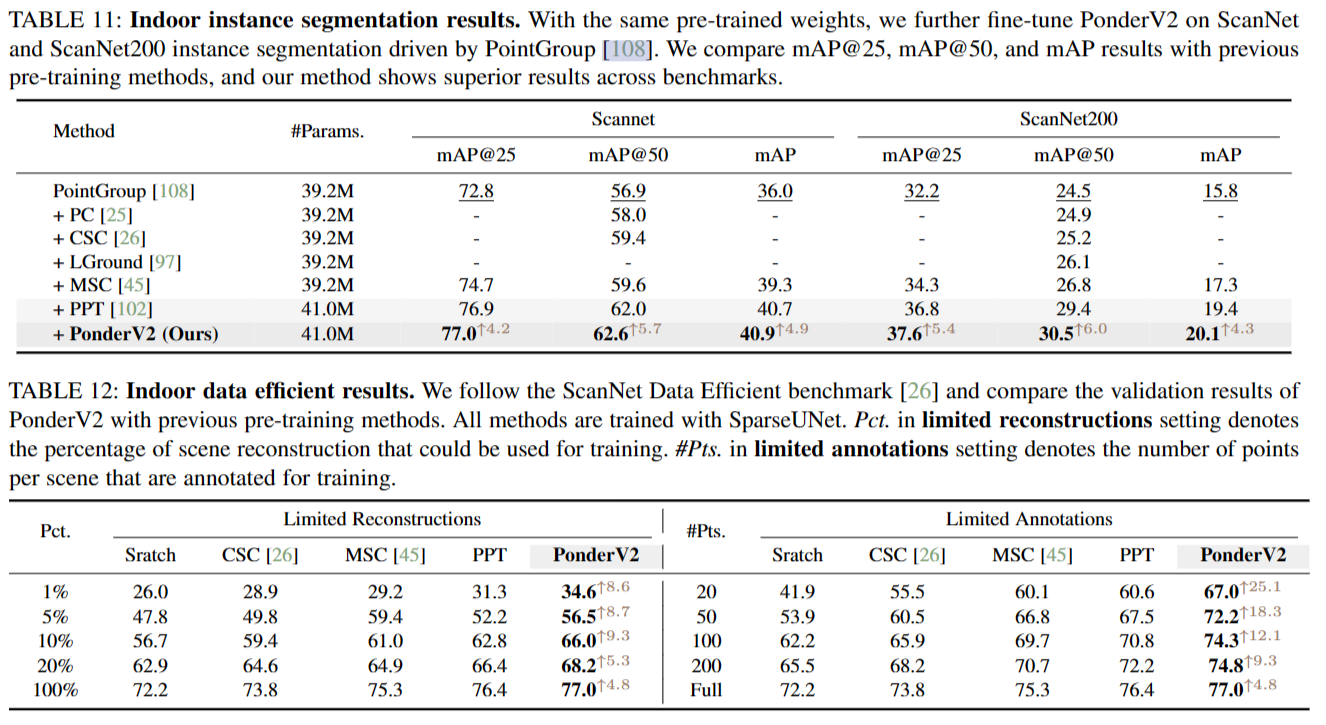
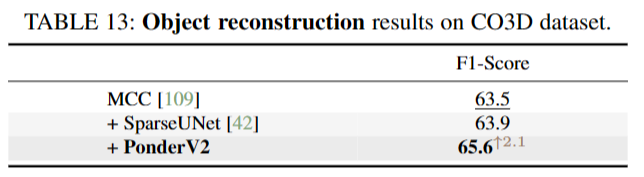
在这种情况下,我们想要预训练一个统一的骨干,可以应用于各种下游任务,它的输入直接是整个场景点云,使上下游模型有一个统一的输入和编码器阶段。我们选择SparseUNet[42]作为$f^{(s)}_e$,这是SpConv[103]对MinkUNet[42]的优化实现,因为它的效率很高,其输出特征f有96个通道。我们主要关注三个被广泛认可的室内数据集:ScanNet [78], S3DIS[104]和Structured3D[105]联合预训练我们的权重。ScanNet和S3DIS代表了3D感知领域最常用的真实世界数据集,而Structured3D是一个合成的RGB-D数据集。由于室内3D视觉可用的数据多样性有限,数据集之间存在不可忽略的域差距,因此朴素联合训练可能无法提高性能。Point Prompt Training(PPT)提出通过给每个数据集赋予自己的批规范层来解决这个问题。考虑到它的有效性和灵活性,我们将PPT与我们通用的预训练范例结合起来,并将PPT作为我们的基线。值得注意的是,PPT在下游任务中实现了最先进的性能,与我们使用的主干相同,即SparseUNet。
在预训练阶段之后,我们丢弃渲染解码器并加载编码器主干的权重以用于下游任务,无论是否有额外的任务特定头部。随后,网络对每个特定的下游任务进行微调和评估。我们主要评估了用于语义分割的平均相交-超并度量(mIoU)和用于实例分割和目标检测任务的平均平均精度(mAP)。
对于统一骨干网的版本,我们的室内实验基于poinept[106],这是一个用于点云感知研究的强大而灵活的代码库。为了公平比较,所有的超参数都与划痕PPT相同。此设置的输入通道数为6,其中包含3个颜色通道和3个表面法线通道。网格尺寸g与0.023米相同。我们还应用了常见的变换,包括随机退出(掩码比为0.8)、旋转、缩放、翻转等。
4.3 EXPERIMENTS FOR OUTDOOR SCENARIOS

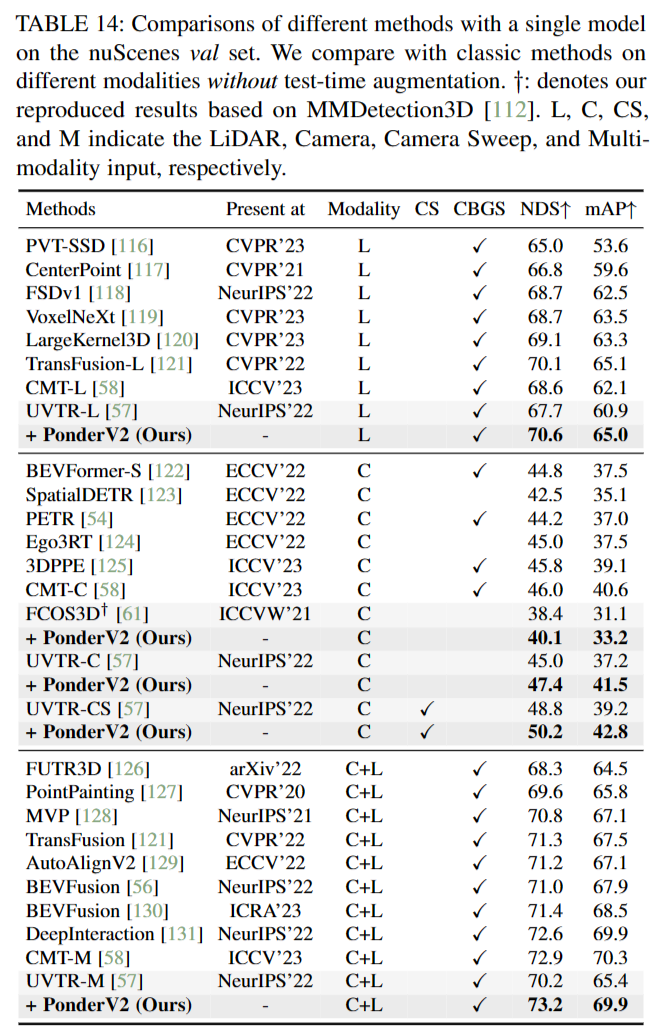
如图8所示,PonderV2在不同输入方式的各种3D户外任务中都取得了显著的改进,这进一步证明了所提出方法的普遍有效性。在本节中,我们将详细介绍PonderV2户外实验的实验细节如下。
我们的代码基于MMDetection3D[112]工具包,并在4个NVIDIA A100 gpu上训练所有模型。输入图像配置为1600 × 900像素,点云体素化的体素尺寸为[0.075,0.075,0.2]。在预训练阶段,我们实现了几种数据增强策略,如随机缩放和旋转。此外,我们部分屏蔽输入,只关注可见区域进行特征提取。图像的掩蔽大小和比率分别配置为32和0.3,点的掩蔽大小和比率分别配置为8和0.8。对于分割任务,我们使用SparseUNet作为我们的稀疏主干f (e)e,对于检测任务,我们使用类似于SparseUNet的编码器部分的VoxelNet[113]作为我们的主干。对于多图像设置,我们使用ConvNeXt-small[114]作为特征提取器f (2d)e。构造形状为180 × 180 × 5的均匀体素表示V。这里的f (d)d是一个3核大小的卷积,作为特征投影层,将V的特征维数减少到32。对于渲染解码器,我们使用φSDF的6层MLP和φRGB的4层MLP。在渲染阶段,每个图像视图随机选择512条光线和96个点。我们保持λRGBand λdepth的损耗比例因子为10。该模型使用AdamW优化器进行了12个epoch的训练,初始学习率分别为点和图像模式的2e−5和1e−4。在消融研究中,除非明确说明,否则在不实施CBGS[115]策略的情况下,对50%的图像数据进行12次微调,对20%的点数据进行20次微调。
Comparisons with Pre-training Methods
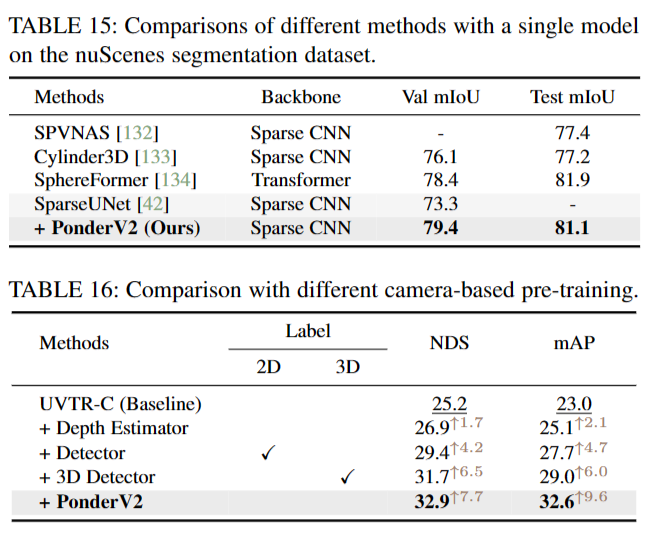
Camera-based Pre-training 在表16中,我们将PonderV2与几种基于摄像机的预训练方法进行了比较:1)Depth Estimator:我们跟随[60]注入3D先验PREPRINT通过深度估计转化为二维特征;2)检测器:在nuImages数据集[111]上使用来自MaskRCNN[135]的预训练权值初始化图像编码器;3) 3D检测器:我们使用广泛使用的单眼3D检测器[61]中的权值进行模型初始化,模型初始化依赖于3D标签进行监督。与之前的无监督或有监督的预训练方法相比,PonderV2展示了优越的知识转移能力,显示了我们基于渲染的借口任务的有效性。
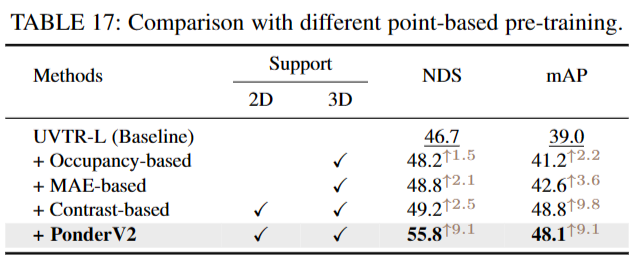
Point-based Pre-training 对于点模态,我们还与表17中最近提出的自监督方法进行了比较:1)基于占用:我们在框架中实现了also[47]来训练点编码器;2)基于mae的:采用领先的执行方法[46],利用倒角距离重构被遮挡点云。3)基于对比(Contrast-based):采用[136]进行比较,采用像素点对比学习,将二维知识整合到三维点中。其中,PonderV2的NDS性能最好。虽然与基于对比的方法相比,PonderV2的mAP略低,但它避免了在对比学习中需要复杂的正负样本分配。
Effectiveness on Various Backbones
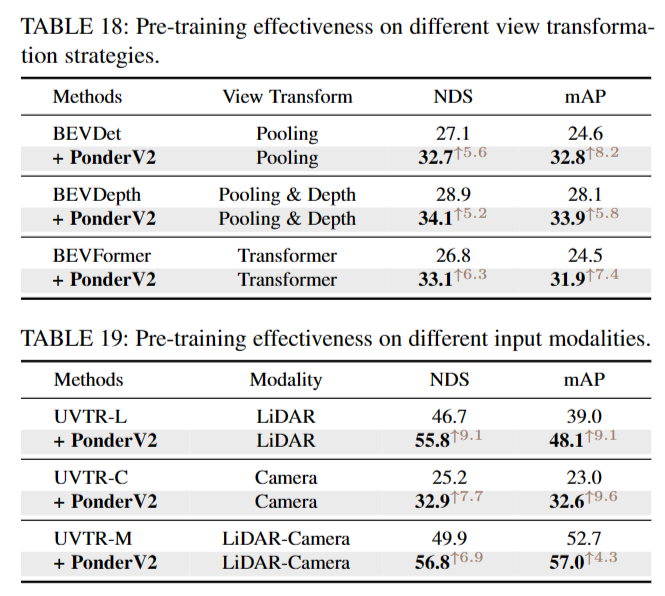
Different View Transformations 在表18中,我们研究了将2D特征转换为3D空间的不同视图转换策略,包括BEVDet[137]、BEVDepth[138]和BEVformer[122]。在不同的变换技术中观察到的改进范围从5.2到6.3 NDS,证明了所提出方法的强大泛化能力
Different Modalities 与之前大多数预训练方法不同,我们的框架可以无缝地应用于各种模式。为了验证我们方法的有效性,我们将UVTR设置为基线,其中包含具有点、相机和融合模式的探测器。表19显示了PonderV2对不同模态的影响。PonderV2可将UVTR-L、uvtr - c和UVTR-M分别提高9.1、7.7和6.9 NDS。
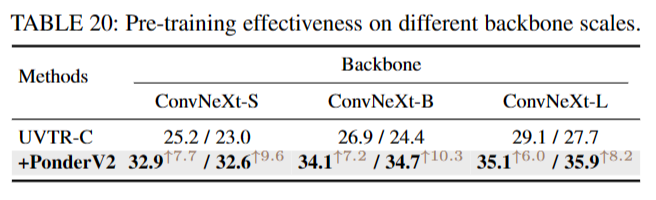
Scaling up Backbones 为了在不同的主干尺度上测试PonderV2,我们采用了一个现成的模型,ConvNeXt及其变体,具有不同数量的可学习参数。如表20所示,可以观察到,通过我们的PonderV2预训练,所有基线都得到了+6.0 ~ 7.7 NDS和+8.2 ~ 10.3 mAP的大幅提高。稳定的增长表明,PonderV2有潜力推动各种最先进的网络。
Ablation Studies
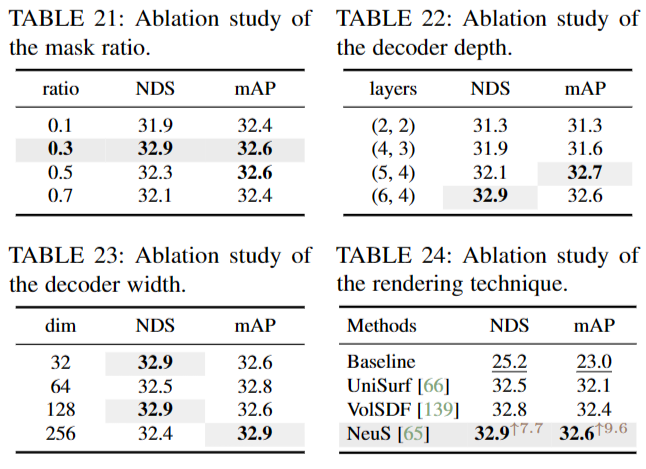
Masking Ratio 表21显示了掩蔽比对相机模态的影响。我们发现0.3的掩蔽比比以前基于mae的方法中使用的比率低,对于我们的方法是最优的。这种差异可能归因于从体表示呈现原始图像的挑战,这比图像到图像的重建更复杂。对于点形态,我们采用考虑到点云固有的空间冗余,掩模比为0.8,如[46]所建议的。
Rendering Design 表22、23和24展示了可微分呈现的灵活设计。在表22中,我们改变了SDF和RGB解码器的深度(DSDF, DRGB),揭示了足够的解码器深度对于成功完成下游检测任务的重要性。这是因为在预训练期间,深度记忆可能有能力充分整合几何或外观线索。相反,如表23所示,解码器的宽度对性能的影响相对较小。因此,为了提高效率,默认尺寸设置为32。此外,我们在表24中探讨了各种渲染技术的效果,它们采用不同的方式进行射线点采样和积累。与UniSurf[66]和news[65]相比,使用news[65]进行渲染记录了0.4和0.1 NDS的改进分别在VolSDF[139]中,通过使用设计良好的渲染方法并受益于神经渲染的进步,可以改善展示学习到的表示。
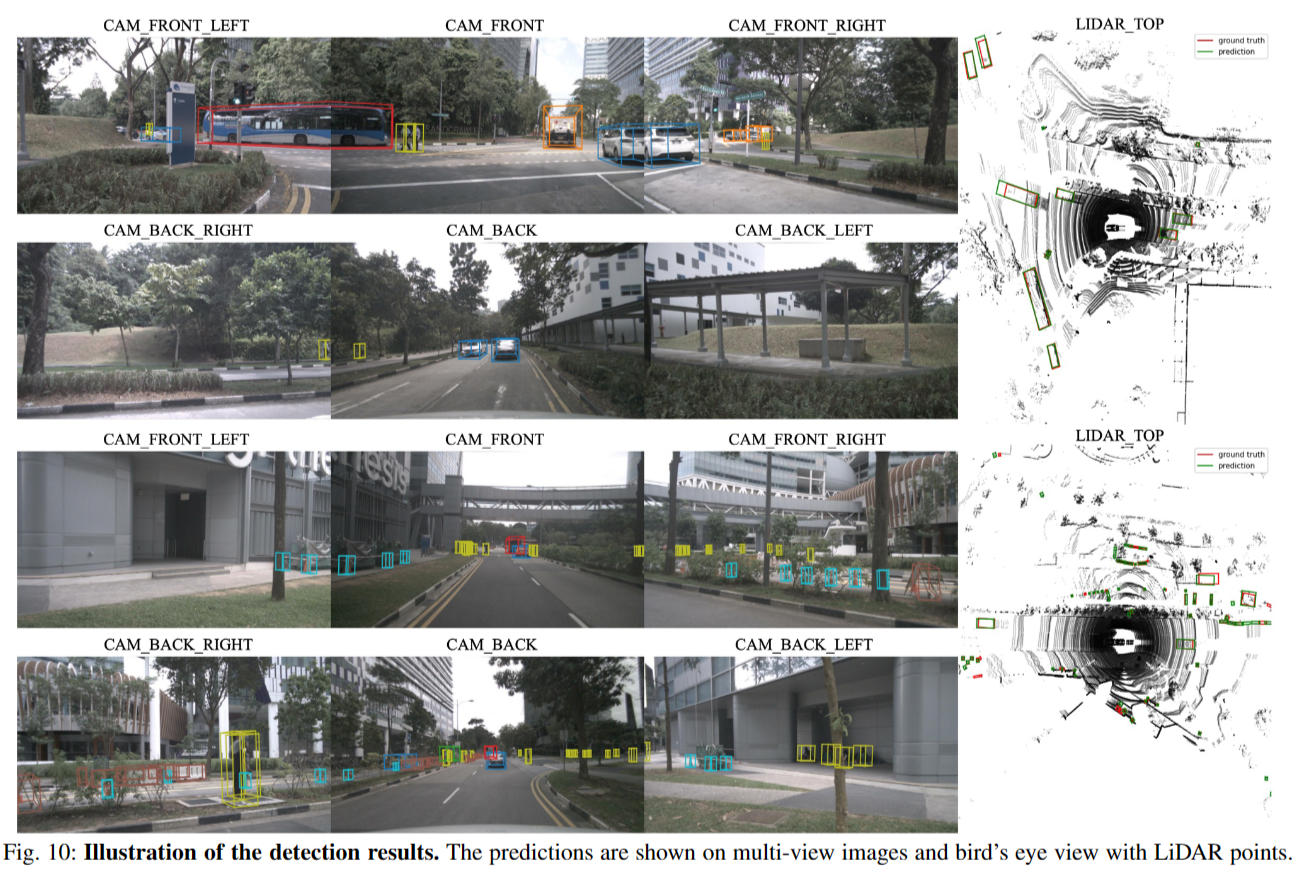
Ⅴ. CONCLUSIONS
在本文中,我们提出了一种新的通用的3D表征学习预训练范式,该范式利用可微神经渲染作为预文本任务。我们的方法名为PonderV2,可以显著提高9个下游室内/室外任务,包括高级感知和低级重建任务。我们亦在超过11项基准测试上达到SOTA的表现。大量的实验证明了该方法的灵活性和有效性。
尽管取得了令人鼓舞的成果,但本文仍然是三维基础模型的起步工作。我们只展示了我们的预训练范式在轻量级和高效骨干(即SparseUNet)上的有效性。评估PonderV2的极限边界,判断它是否或在多大程度上可以导致3D基础模型,这是值得扩大数据集和骨干大小的。此外,在更多下游任务(如重建和机器人控制任务)上充分测试PonderV2也很有趣。这可能会进一步扩大三维表示预训练的应用范围。此外,神经渲染是连接3D和3D世界的桥梁。因此,通过语义渲染等技术将2D基础模型与3D预训练相结合是有价值的。我们希望我们的工作可以帮助在未来的三维基础模型的建立。