〇. Autoencoder [1]
Auto-encoder是一个基本的生成模型,更重要的是它提供了一种encoder-decoder的框架思想,广泛的应用在了许多模型架构中。简单来说,Auto-encoder可以看作是如下的结构:
- Encoder(编码器):它可以把原先的图像压缩成更低维度的向量。
- Decoder(解码器):它可以把压缩后的向量还原成图像,通常它们使用的都是神经网络。
Encoder接收一张图像(或是其他类型的数据)(hidden layer)输出一个低维的vector,它也可称为Embedding或者code,然后将vector输入到Decoder中就可以得到重建后的图像,希望它和输入图像越接近越好,即最小化重建误差(reconstruction error)。Auto-encoder本质上就是一个自我压缩和解压的过程。具体如下图:
- 第一个流程图:假设输入是一张图片,有784个像素,输入一种network的Encoder(编码器)后,输出一组远小于784的code vector,认为这是一种紧凑的表示。
- 第二个流程图:输入是一组code vector,经过network的Decoder(解码器)之后可以输出原始图片。
两者单独来看都是无监督学习,不能独立训练,因为不知道输出是什么。所以将两者结合起来训练。
去噪自编码器(DAE)是一类破坏输入信号,并学习来重建原始未损坏信号的自编码器。一系列方法可以被认为是不同种类的DAE,例如,屏蔽像素或去除颜色通道。
Ⅰ. Abstract
This paper shows that masked autoencoders (MAE) are scalable self-supervised learners for computer vision. Our MAE approach is simple: we mask random patches of the input image and reconstruct the missing pixels. It is based on two core designs. First, we develop an asymmetric encoder-decoder architecture, with an encoder that operates only on the visible subset of patches (without mask tokens), along with a lightweight decoder that reconstructs the original image from the latent representation and mask tokens. Second, we find that masking a high proportion of the input image, e.g., 75%, yields a nontrivial and meaningful self-supervisory task. Coupling these two designs enables us to train large models efficiently and effectively: we accelerate training (by 3× or more) and improve accuracy. Our scalable approach allows for learning high-capacity models that generalize well: e.g., a vanilla ViT-Huge model achieves the best accuracy (87.8%) among methods that use only ImageNet-1K data. Transfer performance in downstream tasks outperforms supervised pretraining and shows promising scaling behavior.
本文表明,掩码自动编码器 (MAE) 是用于计算机视觉的可扩展自我监督学习器。我们的 MAE 方法很简单:我们屏蔽了输入图像的随机patch并重建缺失的像素。它基于两种核心设计。首先,我们开发了一种非对称编码器-解码器架构,其编码器仅对可见patch子集(没有掩码标记)进行操作,以及一个轻量级解码器,它从潜在表示和掩码标记重建原始图像。其次,我们发现掩蔽大部分输入图像,例如 75%,会产生一项非平凡且有意义的自我监督任务。耦合这两种设计使我们能够高效有效地训练大型模型:我们加速训练(超过 3 倍或更多)并提高准确性。我们的可扩展方法允许学习能够很好地泛化的高容量模型:例如,在仅使用 ImageNet-1K 数据的方法中,vanilla Vit-Rouge 模型实现了最佳准确度 (87.8%)。下游任务中的迁移性能优于监督预训练,并且能够有希望扩招到更大规模的模型中。
Ⅱ. Contributions


Enlightenments:
- 随着ViT的提出,将mask tokens和positional embeddings从NLP引入了Vision邻域。
- 与NLP相比,Vision的信息空间的信息密度更加稀疏。比如在从句子中预测缺失的的几个词时,需要进行相当复杂的语义理解;但是在Vision中,当我们从几个patch还原整个图片时,考虑的语义信息很少,大多时候只需要考虑空间信息。文章设计了这样的几个任务,如图2-4。
- 自动编码器的解码器将潜在表示映射回输入,但是NLP和Vision的Decoder扮演的角色不一样。在视觉上,解码器重建像素,因此其输出的语义水平低于普通识别任务。这与语言相反,在语言中,解码器预测包含丰富语义信息的缺失单词。虽然在BERT中,解码器可能是微不足道的MLP,但我们发现,对于图像,解码器的设计在决定学习到的潜在表征的语义水平方面起着关键作用。
因此文章提出了一种简单、有效、可扩展的掩码自编码器(MAE)用于视觉表示学习。我们的MAE从输入图像中屏蔽随机patch,并在像素空间中重建缺失的patch。它具有非对称编解码器设计。我们的编码器仅对patch的可见子集(没有masked)进行操作,我们的解码器是轻量级的,可以从latent representation和masked token一起重建输入(图1)。将masked token转移到我们的非对称编码器-解码器中的小型解码器中,可以大大减少计算量。在这种设计下,非常高的掩蔽比(如75%)可以实现以下比较好的效果:1.优化了精度 2.同时允许编码器只处理一小部分(例如,25%)的patch。这可以将总体预训练时间减少3倍或更多,同样减少内存消耗,使我们能够轻松地将MAE扩展到大型模型。
Ⅲ. Related [2]
3.1 iGPT
OpenAI是一个想把一切GPT化的公司,到了图像这里,自然的想法就是用GPT来训一个图像模型。但是图像是个三维的数据(长x宽x通道),不像文字一样可以变成一维向量的序列。如果直接把图像的三维矩阵拼成二维也可以,但这样数量就太多了。于是iGPT就想到了一个方法,把图像马赛克掉,变成一个个色块,数量一下就减少了,可以像NLP一样愉快地输入到Transformer了:

解决这个核心难点之后就很愉快了,可以无脑用GPT和BERT啦。最后实验下来,BERT在两个数据集的平均表现比GPT差一点点(橙色):
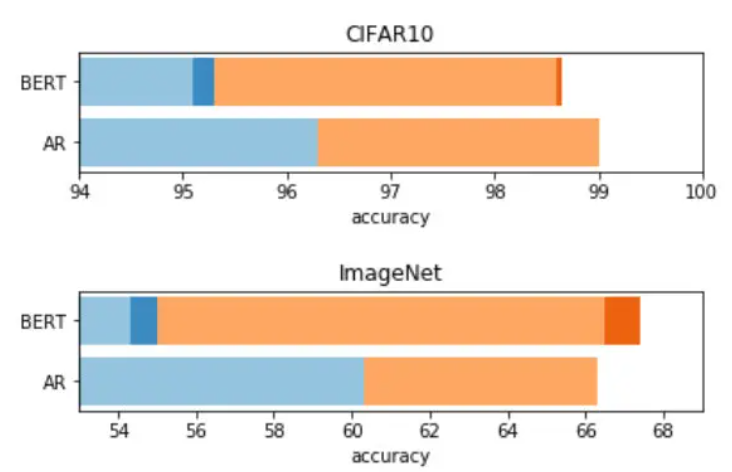
而且BERT因为mask的方式,存在训练预测不一致的问题,OpenAI尝试对测试数据随机mask 5个token,最终ImageNet结果果然上升了一些(红色)。但还是改变不了OpenAI要用GPT统治一切的事实,这篇文章还是用GPT-2(摊手。
iGPT虽然尝试过形式与BERT接近的预训练,但却连一个MAE的关键点都没碰到。其中我觉得问题最大的主要是这个马赛克操作,就拿文中贴的例子来看,都被马赛克成那样子了,还学习什么呢。。。虽然事实证明还是有效果的,但还是从输入上就降低了模型的拟合能力。
但别急,这个问题马上就被解决了。
3.2 ViT
第二个出场的嘉宾,就是红遍大江南北的Vision Transformer——ViT。
它对上面问题的解决办法,就是思想上借鉴了CNN的局部特征抽取,把图片分割成一个个patch,再通过线性映射成一个类似NLP的token embedding。同时为了保留位置信息,加上了可学习的position embedding。
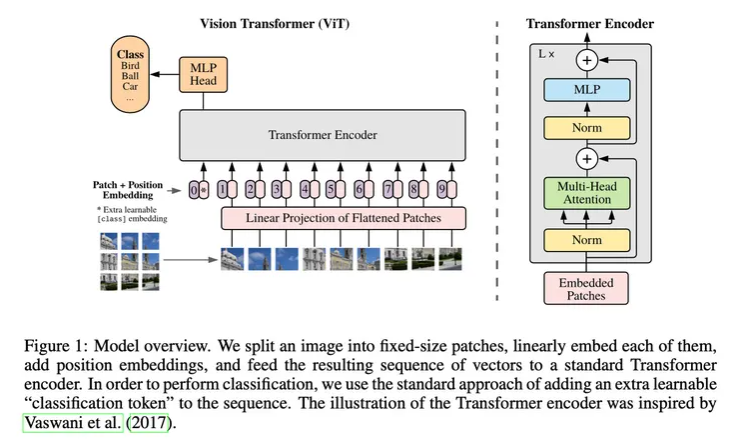
从ViT开始,CVer们终于可以更优雅地使用Transformer了。然而ViT的实验还是跟传统CV一样,进行有监督的预训练。为什么不试试MLM呢?其实他们试过了,但效果不好,所以没重点放出来。
在附录中,ViT其实尝试过三种预训练方法,首先mask掉50%的patch,然后:
- 只预测patch的mean color
- 只预测一个马赛克版的patch
- 用L2损失预测所有pixel
第三种方法真的很接近有木有!!!然而实验发现第三种更差一些,第一种最好,但也比有监督的落后4个点。
看到这里,如果去翻翻MAE的分析实验,就会发现MAE mask 50%之后的效果也很好:
3.3 BEiT
第三位出场的嘉宾是BEiT,微软今年年中的工作,作者之一是知乎的董力大佬。
BEiT的形式同样很接近BERT,只不过用了一个dVAE对patch进行离散化(就像NLP的token也是离散化的)。dVAE需要先在语料上训练出一个encoder和一个decoder,encoder用来当作tokenizer,把图像离散化(对应一个个patch),然后给Transformer输入patch,预测离散后的图像,再用decoder还原。
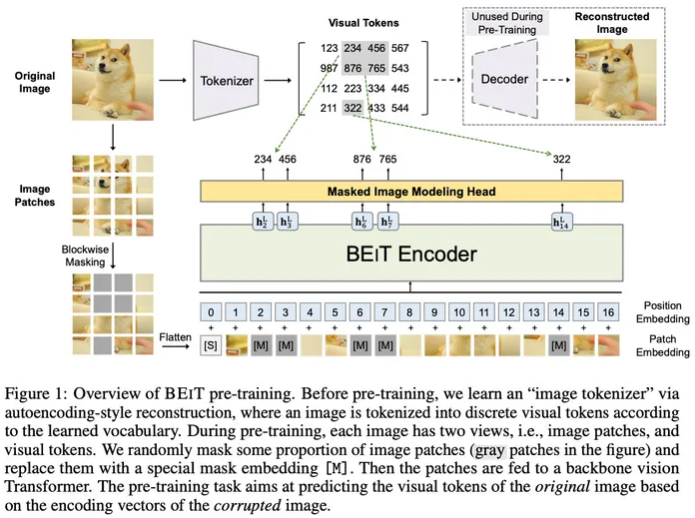
在预训练阶段,最多会mask 40%的patch(同样很接近MAE了)。
另外,作者们其实也试过复原pixel,但效果会有1.8%的下降。对于这个现象,BEiT给出的猜想是,就像多层CNN一样,编码器最终得到的应该是一个更全局、高维的表示,而复现pixel会让后几层太关注局部细节。
Ⅳ. MAE Approach
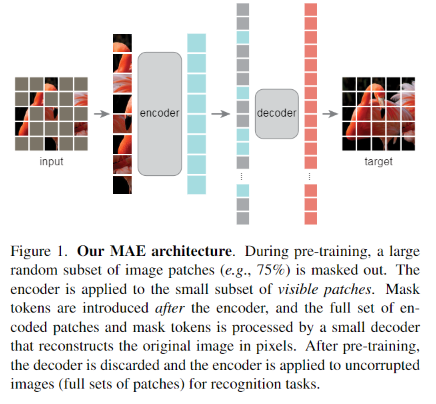
我们的掩码自编码器(MAE)是一种简单的自编码方法,可以在给定部分观测值的情况下重建原始信号。像所有的自编码器一样,我们的方法有一个编码器,将观察到的信号映射到潜在表示,以及一个解码器,从潜在表示重建原始信号。与经典的自编码器不同,我们采用非对称设计,允许编码器仅对部分观察到的信号(没有掩码令牌)进行操作,并采用轻量级解码器,从潜在表示和掩码令牌重建完整信号。图1说明了下面介绍的思想。
Masking.
跟ViT一样将图片均匀分成多个patch,随机选取patch进行mask,不进行替换,遵循均匀分布。称为”random sampling”.
具有高mask比(即去除斑块的比例)的随机采样在很大程度上消除了冗余,从而创建了一个不能通过从可见的邻近斑块外推轻松解决的任务(见图2 - 4)。均匀分布防止了潜在的中心偏差(即在图像中心附近有更多的掩蔽斑块)。最后,高度稀疏的输入为设计高效的编码器创造了机会,下面将介绍。
MAE encoder.
编码器是一个ViT,但是只会输入可见的、未被masked的patch。然后通过一个线性函数将位置编码嵌入到patch,然后输入一系列Tranformer中去。但是我们只需要输入完整集的一小部分(可见部分),使得运算量和运算难度大幅降低。
MAE decoder.
解码器输入(i) encoded visible patches and (ii) mask tokens.如图一。每个mask token是一个共享的可学习向量,表示存在待预测的缺失补丁。我们为这个完整集合中的所有标记添加位置嵌入;如果没有这个,掩码令牌将没有关于它们在图像中的位置的信息。解码器有另一系列的Transformer块。
MAE解码器仅在预训练期间用于执行图像重建任务(仅使用编码器来生成用于识别的图像表示)。因此,解码器架构可以以独立于编码器设计的方式灵活设计。我们尝试了非常小的解码器,比编码器更窄更浅。例如,我们的默认解码器每个令牌的计算量 <10%。通过这种非对称设计,全套令牌仅由轻量级解码器处理,这显着减少了预训练时间。
Reconstruction target.
MAE会输出被masked的patch的像素值,通过一个像素值向量代表一个patch。解码器的最后一层是一个线性投影,其输出通道的数量等于一个patch中的像素值的数量。解码器的输出被reshape以形成重建图像。我们的损失函数计算像素空间中重建图像和原始图像之间的均方误差(MSE)。我们只在masked patch上计算损失,类似于 BERT。
我们还研究了一种变体,其重建目标是每个掩码补丁的归一化像素值。具体来说,我们计算补丁中所有像素的均值和标准差,并使用它们来规范化这个补丁。在我们的实验中,使用归一化像素作为重建目标可以提高表示质量。
Simple implementation.
MAE不需要任何专门的稀疏操作。首先,我们为每个输入补丁生成一个标记(通过添加位置嵌入的线性投影)。接下来,我们随机打乱令牌列表,并根据屏蔽比率删除列表的最后一部分。这个过程为编码器生成一小部分标记,相当于采样补丁而不进行替换。编码后,我们将一个掩码令牌列表添加到编码补丁列表中,并取消这个完整列表(反转随机洗牌操作),以使所有令牌与其目标对齐。解码器应用于这个完整的列表(添加了位置嵌入)。如前所述,不需要稀疏操作。这个简单的实现引入的开销可以忽略不计,因为变换和解变换操作非常快。
Ⅴ. ImageNet Experiments
Baseline: ViT-Large. 我们使用viti - large (viti - l /16)[16]作为消融研究的主干。viti - l非常大(比ResNet-50[25]大一个数量级),容易过拟合。以下是从头开始训练的ViT-L与根据基线MAE进行微调的ViT-L的比较:
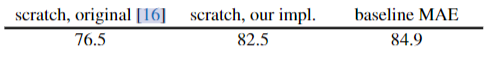
4.1. Main Properties
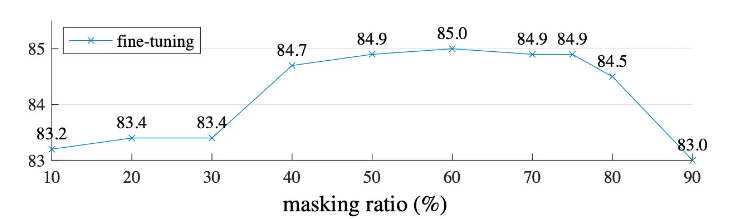
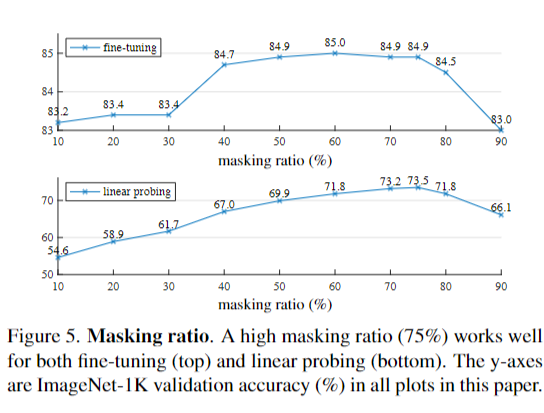
Masking ratio.
图5显示了掩蔽比的影响。最佳比例高得惊人。75%的比例对线性探测和微调都很好。这种行为与BERT相反,BERT的典型掩蔽比为15%。我们的掩蔽率也远高于计算机视觉领域的相关研究6,16,2。
Decoder design.
Overall, our default MAE decoder is lightweight. It has 8 blocks and a width of 512-d ( gray in Table 1). It only has 9% FLOPs per token vs. ViT-L (24 blocks, 1024-d). As such, while the decoder processes all tokens, it is still a small fraction of the overall compute.
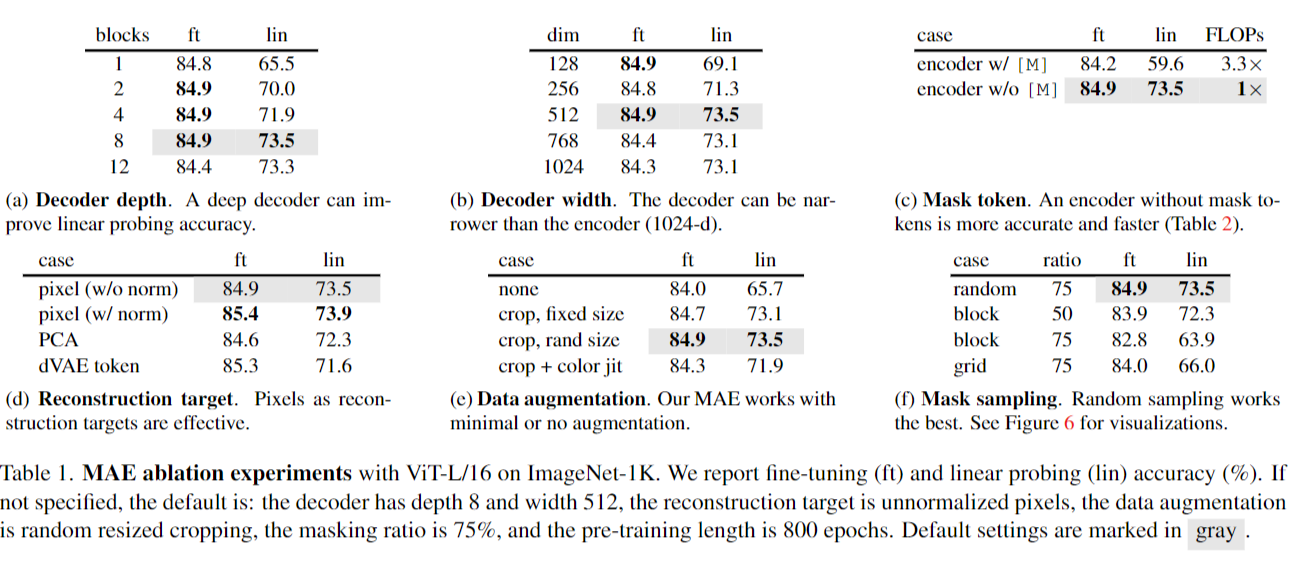
Mask token.
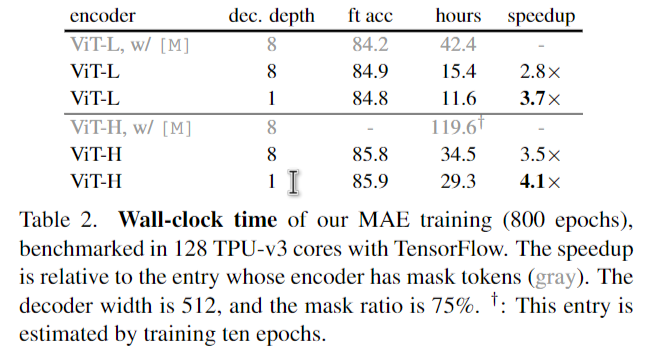
我们的MAE的一个重要设计是跳过编码器中的mask token[M],并稍后在轻量级解码器中应用它。表1c研究了这种设计。
此外,通过跳过编码器中的掩码令牌,我们大大减少了训练计算。在表1c中,我们将总体训练FLOPs降低了3.3倍。在我们的实现中,这导致了2.8倍的时钟加速(见表2)。
Reconstruction target.
我们在表1d中比较了不同的重建目标。到目前为止,我们的结果是基于没有(每个补丁)规范化的像素。使用带有归一化的像素可以提高精度。这种逐补丁归一化在局部增强了对比度。在另一种变体中,我们在patch空间中执行PCA,并使用最大的PCA系数(这里是96)作为目标。这样做会降低准确性。两个实验都表明高频分量在我们的方法中是有用的。
我们基于像素的MAE比标记化简单得多。dVAE标记器需要更多的预训练阶段,这可能取决于额外的数据(250M图像[50])。dVAE编码器是一个大型卷积网络(ViT-L的40% FLOPs),并且增加了不小的开销。使用像素不会受到这些问题的困扰。
Data augmentation.
omiited.
Mask sampling strategy.
在表1f中,我们比较了不同的掩码采样策略,如图6所示。[2]中提出的逐块屏蔽策略倾向于去除大块(图6中间)。我们的具有块屏蔽的MAE在50%的比例下工作得相当好,但在75%的比例下会退化。该任务比随机抽样更难,因为观察到更高的训练损失。重建的图像也更加模糊。我们还研究了网格智能采样,它定期保持每四个补丁中的一个(图6右)。这是一个更简单的任务,训练损失更小。重建更加清晰。但是,表示质量较低。简单随机抽样最适合我们的MAE。它允许更高的掩蔽比,这提供了更大的加速效益,同时也享有良好的准确性。
Training schedule.
omitted.
4.2 Comparisons with Previous Results
Omitted.
4.3. Partial Fine-tuning
Omitted.
Ⅴ. Transfer Learning Experiments
Omitted.