Ⅰ. Abstract
Training Deep Learning (DL) model requires multiple resource types, including CPUs, GPUs, storage IO, and network IO. Advancements in DL have produced a wide spectrum of models that have diverse usage patterns on different resource types. Existing DL schedulers focus on only GPU allocation, while missing the opportunity of packing jobs along multiple resource types. We present Muri, a multi-resource cluster scheduler for DL workloads. Muri exploits multi-resource interleaving of DL training jobs to achieve high resource utilization and reduce job completion time (JCT). DL jobs have a unique staged, iterative computation pattern. In contrast to multi-resource schedulers for big data workloads that pack jobs in the space dimension, Muri leverages this unique pattern to interleave jobs on the same set of resources in the time dimension. Muri adapts Blossom algorithm to find the perfect grouping plan for single-GPU jobs with two resource types, and generalizes the algorithm to handle multi-GPU jobs with more than two types. We build a prototype of Muri and integrate it with PyTorch. Experiments on a cluster with 64 GPUs demonstrate that Muri improves the average JCT by up to 3.6× and the makespan by up to 1.6× over existing DL schedulers.
训练深度学习 (DL) 模型需要多种资源类型,包括 CPU、GPU、存储 IO 和网络 IO等等。深度学习的进步催生了了大量的模型,这些模型在不同的资源类型上具有不同的使用模式。现有的DL调度器只关注GPU的分配,却错过了将作业整合到多个资源类型上的机会。
因此我们提出了 Muri,一种用于 DL 工作负载的多资源集群调度器。Muri利用DL训练作业的多资源交错来实现高资源利用率,并减少作业完成时间(JCT)。DL作业具有独特的分阶段迭代计算模式。与在空间维度上打包作业的大数据工作负载的多资源调度器不同,Muri利用这种独特的模式在时间维度上对同一组资源上的作业进行交错。Muri采用Blossom算法为单单GPU作业作业寻找两种资源类型的的完美分组方案,并将该算法推广到处理两种以上资源类型的多GPU作业。我们构建了一个Muri的原型,并将其与PyTorch集成。在具有64个GPU的集群上进行的实验表明,与现有的DL调度器相比,Muri将平均JCT提高了3.6倍,最大完成时间提高了1.6倍。
CCS CONCEPTS
- Computer systems organization → Cloud computing
- Computing methodologies → Machine learning.
Ⅱ. Introduction
深度学习(DL)越来越多地集成到以数据为中心的互联网应用和服务中。训练深度学习模型已经成为数据中心的一项重要工作。企业构建 GPU 集群来运行深度学习训练作业。用户向集群提交深度学习训练作业,集群调度程序对作业进行调度和资源分配,提高集群效率和作业效率。
这些调度器中一个关键的潜在假设是GPU是DL训练作业的瓶颈,因此它们在调度作业时只需要考虑GPU,而不需要全面考虑其他资源类型。然而,在实践中,深度学习训练需要多种类型的资源,包括:
- 从本地或远程存储读取训练数据以供工作节点使用的存储输入/输出
- CPU 用于预处理和模拟(例如在强化学习中)
- GPU 用于前向和反向传播
- 网络输入/输出用于分布式训练中的工作节点之间的梯度同步
对于许多早期的DL模型(如ResNet)来说,GPU是模型训练的瓶颈——这就是为什么现有的DL调度器专注于GPU分配的原因。然而,随着近年来深度学习的快速发展,这种假设不再成立。现在各种各样的深度学习模型在模型大小和类型上变化很大。训练不同的深度学习模型需要不同的资源,有时GPU并不是唯一的瓶颈资源,其他资源也可能成为深度学习工作的瓶颈。例如,随着在物联网(IoT)场景的边缘设备中部署深度学习应用的需求不断增长,对微型深度学习模型的研究变得越来越流行。在GPU上训练一个小模型速度很快,瓶颈通常存在于存储IO身上,即从存储中读取样本的速度不够快,不足以使GPU饱和。训练强化学习(RL)模型依赖于CPU进行仿真,例如在训练机器人控制策略时模拟机器人和环境。与在GPU上执行神经网络计算相比,模拟可能需要更长的时间,这使得CPU成为瓶颈。对于大型深度学习模型的分布式训练任务,网络IO通常是瓶颈。在某些情况下,90%的训练时间花费在梯度同步的组网上。仅基于GPU调度深度学习训练作业使资源远远没有得到充分利用。
在本文中,我们提出了Muri,一个用于深度学习工作负载的多资源集群调度器,它利用多资源交错的机会来实现高资源利用率并减少深度学习工作负载的作业完成时间(JCT)。与现有的深度学习调度程序不同,在调度深度学习训练作业时,Muri利用多种资源类型来提高整体资源利用率。当训练任务培训工作在一种资源类型上遇到瓶颈时,其他类型的资源未得到充分利用,可以将它们分配给其他工作。Muri的核心思想是将多个在不同资源类型上出现瓶颈的作业穿插在一起,从而有效地利用资源,减少作业排队时间,从而减少JCT。
在过去,大数据工作负载(如Spark作业)的集群调度器考虑了多资源调度。然而由于大数据作业的多样性,先前的多资源调度器通常使用每种资源类型的最大使用量作为每个作业的需求,并在空间中为作业分配资源。当作业运行时,分配给作业的资源不会与其他作业共享。
我们的观察到的重点是,深度学习训练工作具有独特的分阶段迭代计算模式,可以实现细粒度的多资源交错。具体来说,深度学习训练任务由许多迭代组成,每个迭代由一系列阶段组成,如数据加载、预处理、向前和向后传播以及梯度同步。每个阶段通常高度利用一种特定的资源类型,这使得通过交叉不同作业的不同阶段,可以将多个作业打包在同一组资源上。由于采用迭代计算模式,这样的打包决策只需要在作业级别完成,这降低了细粒度打包的调度开销,使其可行。
Muri的主要技术挑战是在多种资源类型和多GPU作业存在的情况下最大限度地提高交错效率。对于单GPU作业的基本情况,我们将问题表述为k维最大加权匹配问题(k-dimensional maximum weighted matching problem),这个问题可以用Blossom算法来解决,找到两种资源类型的完美匹配策略。我们设计了一个基于Blossom算法的多轮算法来处理两种以上的资源类型。对于多GPU作业,一个作业可能属于不同GPU上的不同打包组,作业内部worker同步和作业间交错之间的交互会引入额外的打包开销。该算法避免了跨组封装,使封装开销最小化。
多资源交织不同于最近在深度学习训练中的多资源流水线研究。后者侧重于重叠同一作业的不同阶段的资源使用,例如ByteScheduler和BytePS中的重叠梯度同步(network)和前向传播(GPU)。当作业在特定资源类型上遇到瓶颈时(例如对于通信计算比高的作业GPU利用率较低),或者无法完全重叠不同资源类型的使用(例如,由于数据依赖性),资源仍然可以在作业内部流水线中得到充分利用。Muri的关键新颖之处在于它引入了作业间的交错,从而重叠了不同作业的资源使用情况。在调度多个作业时,Muri使用作业间交错来提高集群的整体资源利用率,从而提高makespan和JCT。
Contributions
-
我们确定了使用多种资源类型的交叉DL训练工作的机会。
-
基于Blossom算法设计了一种新的调度算法,该算法考虑每个作业的多资源使用情况,对作业进行分组,最大限度地提高交叉效率。
-
提出了Muri,一个用于深度学习工作负载的集群调度器,它利用多资源交错。在拥有64个V100 GPU的集群上进行的实验表明,与现有的DL调度器相比,Muri将平均JCT提高了3.6倍,最大扩展时间提高了1.6倍,尾部JCT提高了3.8倍[15,25,45]。在更大的轨迹上进行轨迹驱动的模拟表明,Muri将平均JCT提高了6.1倍,最长时间提高了1.6倍,尾部JCT提高了5.4倍。
Ⅱ. Motivation
2.1 Limitations of Existing DL Schedulers
许多深度学习调度器已经被提出用于深度学习训练工作量。已知当运行时间已知时,最短作业优先(SJF)和最短剩余时间优先(SRTF)可以最小化平均JCT,而当运行时间未知时,最小达到服务(LAS)和Gittins指数是有效的。几个深度学习调度程序扩展了这些算法,通过考虑每个作业使用的GPU数量和对分布式训练吞吐量很重要的位置偏好来调度深度学习训练作业。例如,Tiresias将SRTF、LAS和Gittins索引分别扩展为最短剩余服务优先(SRSF)、2D-LAS和2D-Gittins索引,用于深度学习作业调度。这些解决方案在作业运行时专门为作业分配GPU。
最近的一些工作探索了用于DL调度的GPU共享。当 GPU 是 DL 作业中使用的唯一资源时,这是有效的。然而,由于 DL 作业使用各种资源类型,并且不同的作业受到不同资源类型的瓶颈,仅考虑 GPU 共享甚至会降低性能。我们用一个例子来说明只考虑GPU共享的局限性。假设我们有两个作业,每个作业的运行时间为1个时间单位。如果没有GPU共享,我们使用先进先出(FIFO)来调度这些作业。一项工作在一个时间单位内完成;另一个作业等待1个时间单元,并使用1个时间单元运行,即其JCT为2个时间单元。平均JCT为(1+2)/2 = 1.5时间单位。假设这两个作业可以放在一个GPU中,但它们会竞争其他资源(例如存储IO)。因此,当它们并发运行时,它们的运行速度只有一半。通过GPU共享,每个作业的JCT变成了2个时间单位。因此,平均JCT是2个时间单位,这甚至比单独运行它们更糟糕。
2.2 Opportunities & Challenges
Opportunity: multi-resource interleaving.
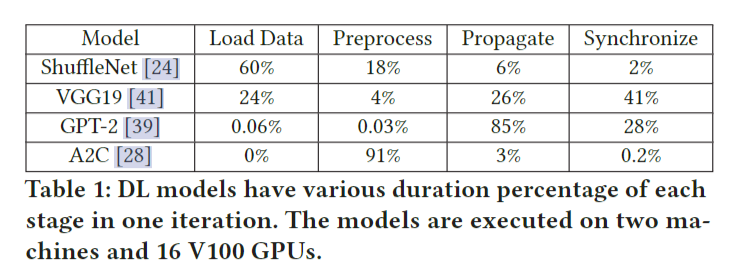
深度学习训练作业使用多种资源类型,并且使用模式是分阶段的。表1显示了四种流行的深度学习模型的持续时间百分比。我们在两台机器和16个V100 GPU上执行这些模型。我们使用PyTorch Profiler来记录每个操作符的类型、持续时间和资源类型。我们通过将每个阶段的时间除以一次迭代的持续时间来计算持续时间百分比。请注意,一个DL模型中四个阶段的持续时间百分比的总和可能不是100%,主要有两个原因。首先,一个深度学习训练任务重叠不同的阶段,以减少一次迭代的持续时间,例如重叠反向传播和梯度同步。因此,持续时间百分比的总和可能大于100%。其次,阶段之间存在一些空闲时间,例如CUDA调度器可能会延迟计算内核的执行。空闲时间增加了一次迭代的持续时间,从而导致持续时间百分比的总和变小。分析结果证实,每个阶段主要使用一种资源类型,即存储IO用于数据加载,CPU用于预处理,GPU用于前向和后向传播,网络IO用于梯度同步。此外,表1说明了不同的DL模型在不同的资源类型上存在瓶颈,而不仅仅是GPU。
关于资源共享有两个层面的概念,即空间共享和时间共享。首先,对于每种资源类型,当一个作业不能充分利用一种类型的资源时,它可以与其他作业共享该资源。一种类型的资源可以分成多个部分,每个作业拥有一个部分,即空间共享。第二,在资源类型上,DL训练任务可以相互交错,跨时间共享不同的资源,即时间共享。即使DL训练作业高度利用一种类型的资源(例如,GPU),它也可能不会一直使用这些资源(例如,在数据加载,预处理和梯度同步期间GPU利用率较低)。通过小心地改变作业的阶段,多个作业可以交错使用不同类型的作业。
在大数据工作负载(如Spark作业)的集群调度中,已经研究了多资源调度。但是以前的多资源调度解决方案只能执行粗粒度调度空间中的多资源打包。由于大数据作业是多种多样的,因此在制定调度决策时,它们将每种资源类型的最大使用量作为每个作业的需求,并且不会在同一组资源上并发运行作业。
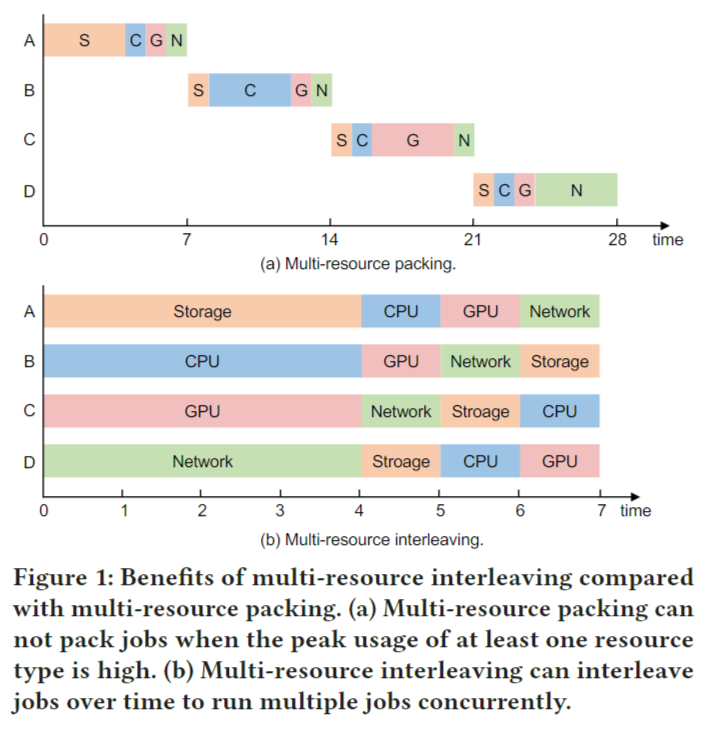
我们利用DL训练任务独特的阶段迭代计算模式,使细粒度的多资源及时交错。图1说明了多资源交错的好处。有四个作业,分别是A、B、C和d。该图绘制了每个作业一次迭代的资源使用情况。这四个作业在不同的资源类型上存在瓶颈。如果将资源专门分配给它们,则每次只能运行一个作业。当至少一种资源类型的峰值使用率很高时,多资源打包不能打包作业。它必须分别运行这四个作业,如图1(a)所示。另一方面,如图1(b)所示,通过交错使用不同的资源类型,这四个作业可以重叠并并发运行,与单独运行它们相比,这增加了资源利用率,并将吞吐量提高了4倍。
由于每个作业的计算都是迭代的,多资源交错的调度决策只需要在作业级别执行一次,然后作业可以使用交错计划运行多次迭代,从而降低调度开销并使这种调度策略对于具有大量作业的集群是可行的。然而,实现这个想法需要解决几个技术挑战。
Multi-resource interleaving vs. pipelining
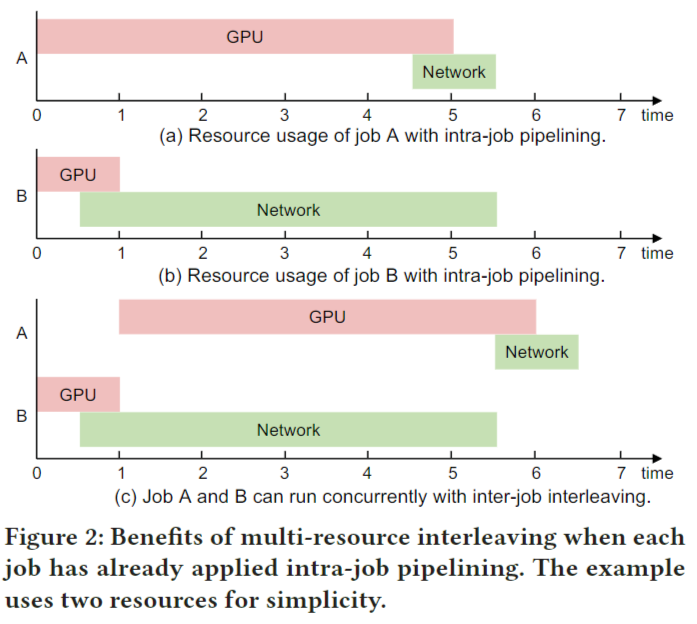
图1显示了一个理想的案例用于说明多资源交错的思想和好处。在实践中,深度学习训练作业采用流水线方式来重叠不同资源的使用。例如,在训练当前批(即流水线存储IO和GPU)时,通常会预取下一批的训练样本,并与正向和反向传播(即流水线网络IO和GPU)重叠梯度同步。我们注意到现有工作中的多资源流水线和本文中的多资源交织的思想是正交的,其中多资源流水线利用了工作内部方面而多资源交织利用作业间方面。重要的是,当作业在特定资源上遇到瓶颈时(例如,具有高通信与计算比的作业的GPU利用率较低),或者不能完全重叠不同资源的使用(例如,由于数据依赖性),作业内部流水线的资源仍然未得到充分利用。例如,图2(A)中作业A未充分利用网络,图2(B)中作业B未充分利用GPU。如图2(c)所示,将作业A和作业B交叉运行,与单独运行它们相比,可以提高11/6.5 = 1.7倍的吞吐量。
我们注意到,图2中的情况仍然是简化的,因为每种资源类型要么已使用,要么未使用。在现实中,某些资源类型(如CPU)在整个训练过程中使用的利用率是不同的(如数据预处理时CPU利用率高,训练时CPU利用率低)。关键的一点是,当不同的类型在不同的工作中被高度利用时,要交叉使用这些阶段。
Example
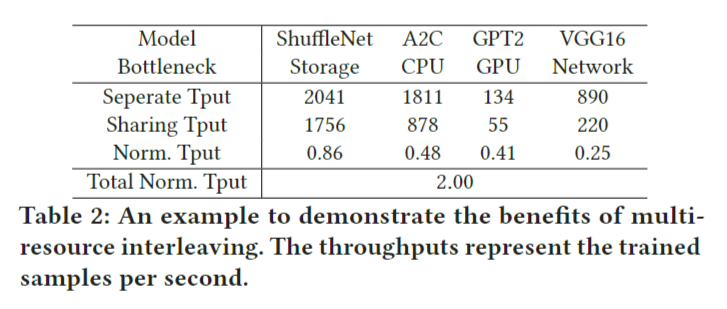
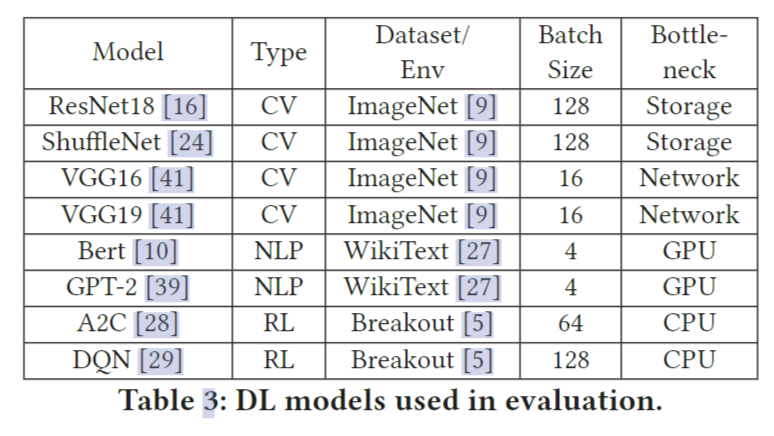
为了展示多资源交织的潜力,我们考虑了四个训练任务,分别训练ShuffleNet、A2C、GPT2和VGG16。批大小和数据集列在表3中。每台机器配置8个NVIDIA Tesla V100 gpu, 2个Intel Xeon(R) Platinum 8260 cpu和一个Mellanox CX-5单端口网卡。训练数据存储在本地。训练四个任务在16个GPU上完成。这四个任务在不同的资源类型上有瓶颈:ShuffleNet的存储IO, A2C的CPU, GPT-2的GPU, VGG16的网络IO。表2列出了分别训练和一起训练时的吞吐量。当这四个作业在多资源交错的情况下一起运行时,我们计算标准化吞吐量,即并发运行时的吞吐量除以每个作业单独运行时的吞吐量。我们将四个作业的归一化吞吐量加起来,结果是2x,这表明多资源交错的加速提高了2x。它没有达到4x,因为四个作业的每次迭代时间是不同的,并且四个作业不能完全重叠在不同的阶段。然而,它展示了使用多资源交错改进作业调度的潜力。
请注意,多资源交错并不会显著增加GPU内存的使用,因为中间数据消耗了大部分GPU内存[42],而多资源交错会交叉这些数据的出现。对于上面的例子,与GPT2相比,交叉四个作业只增加了GPU内存消耗的峰值<10%,GPT2消耗了四个模型中最多的GPU内存。因此,多资源交错是提高深度学习作业资源利用率的可行方法。
Challenges for multi-resource interleaving.
实现多资源交错存在一些技术难题。首先,阶段的重叠会影响每个阶段的处理速度,从而影响每次迭代。因此,不同的交错模式,即何时以及以何种方式执行这些阶段,可以提供不同的加速效果。其次,我们需要一种方法来捕捉交错一组作业的效用,反映一个作业与一个作业的资源利用率是否比另一个作业更好。准确捕获不同作业组的交错效用对调度质量至关重要。第三,对于运行许多DL作业的集群,分组作业的组合数量呈指数级增长。基于不同组的交错效用,我们需要决定如何对作业进行分组,以最大化集群范围的资源利用率并最小化JCT。第四,分布式训练作业在多个gpu上运行,使情况更加复杂。如果一个分布式的训练作业在不同的gpu上属于不同的组,则该作业的每个worker需要与不同的job交错,并且不同的worker需要相互同步。这可能会带来额外的同步开销。
Ⅲ. Muri Overview
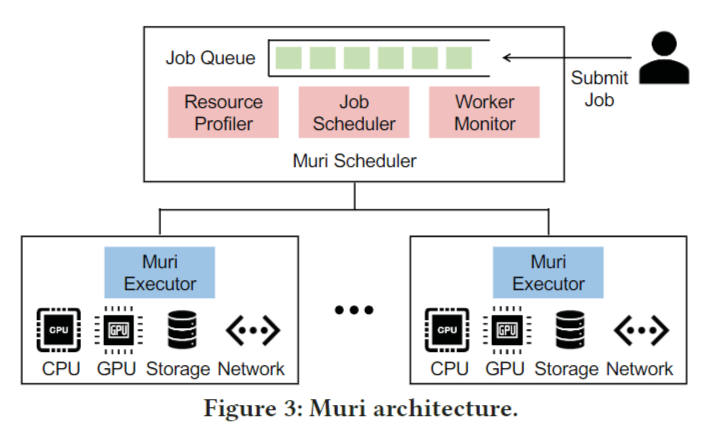
Muri是用于DL工作负载的多资源集群调度器。它利用DL作业的多资源使用模式,实现高效的多资源共享。Muri的核心是利用深度学习作业的分阶段迭代计算模式,在时间上以细粒度的方式在多个资源上交错进行深度学习作业。这使得多个DL作业可以在同一组资源上并发运行,从而提高了资源利用率,减少了作业排队时间,并减少了JCT。Muri的体系结构如图3所示。
3.1 Muri scheduler.
用户向Muri调度程序提交DL训练任务。Muri调度器维护一个作业队列来缓冲提交的作业,并做出作业调度决策。调度程序包括三个组件,分别是资源分析器、作业调度程序和工作监视器(resource profiler, job scheduler, and worker monitor.)。
资源分析器。资源分析器分析每个作业的每种资源类型的资源使用情况,并估计不同作业组的交错效率,这将作为调度算法的输入。当作业首次提交时,作业分析器对作业进行几次演练以测量资源使用情况和执行持续时间。对于以前已提交的训练相同模型的作业,可以重用以前收集的资源配置文件,而无需重新分析。对于给定的作业组,资源分析器使用资源配置文件来估计交错效率。
作业调度器。作业调度器将作业从作业队列调度到集群中的机器。调度程序在作业到达和作业完成等事件时被周期性地调用。基于不同作业组的交织效率,调度程序采用多轮作业分组算法,决定哪些作业分组共享资源,使资源利用率最大化。该算法能够找到具有两种资源类型的单gpu作业的最优分组策略。我们扩展了该算法以处理两种以上的资源类型并支持多gpu作业。该算法避免了多gpu作业的跨组打包,以最小化交错开销。
多轮作业分组算法是一种用于优化和调度多个作业(通常是计算任务或工作流程)的算法。它的目标是有效地分配计算资源,以最大程度地提高系统的整体性能和资源利用率。多轮作业分组算法通常包括以下步骤:
- 作业分类:将一组待执行的作业按照某种规则或策略进行分类或分组。这可以是根据作业的优先级、资源需求、执行时间估计等标准进行分类。
- 分组形成:在根据分类结果将作业分组成小批次(或轮次)。每一轮中的作业可以被同时提交或执行。
- 调度策略:对每一轮中的作业执行某种调度策略,以确定它们的执行顺序和资源分配。这可以包括按照优先级分配资源、最小化等待时间、最大化资源利用率等目标。
- 执行和监控:执行每个分组中的作业,同时监控其进度和资源使用情况。
- 重复:根据系统状态和作业队列的变化,反复执行前面的步骤,以不断优化和调整作业分组和资源分配。
多轮作业分组算法的主要目标是在有限的资源下有效地管理和执行作业,以最大程度地提高系统的吞吐量、降低延迟和提高资源利用率。这种算法通常应用于大规模计算集群、云计算环境、超级计算机和分布式系统等场景,以处理复杂的计算工作负载。不同的多轮作业分组算法可以根据具体的需求和系统特性进行定制和优化。
工作节点监控器。工作节点监控器收集每台机器的资源信息并跟踪每个作业的进展情况。资源信息包括每台机器上可用资源的容量。对于GPU集群上的深度学习工作负载,工作节点监控器还收集每台机器上GPU的数量和拓扑结构,以便调度器可以使用这些信息来安排多GPU作业。监控器在计划的作业完成时通知调度器,释放的资源可以用于队列中的作业。
3.2 Muri executor.
每台机器上都有一个Muri执行器。执行器接收来自作业调度器的作业和分组策略,并根据分组策略在机器上执行作业。执行器还向工作节点监控器报告资源利用情况和作业进展情况。一旦在训练过程中发生故障,执行器将向工作节点监控器报告故障信息并协助处理故障。
Ⅳ. Muri Design
在本节中,我们首先讨论如何将具有两种资源类型的单GPU深度学习训练作业分组,以获得有关多资源交错的见解。然后,我们描述如何处理多GPU作业和多于两种资源类型的一般情况。
4.1 Insights from Single-GPU Jobs with Two Resource Types
我们首先考虑将单 GPU 作业与两种资源类型交错的基本情况。Muri 的调度算法建立在基本案例之上。
Interleaving jobs.
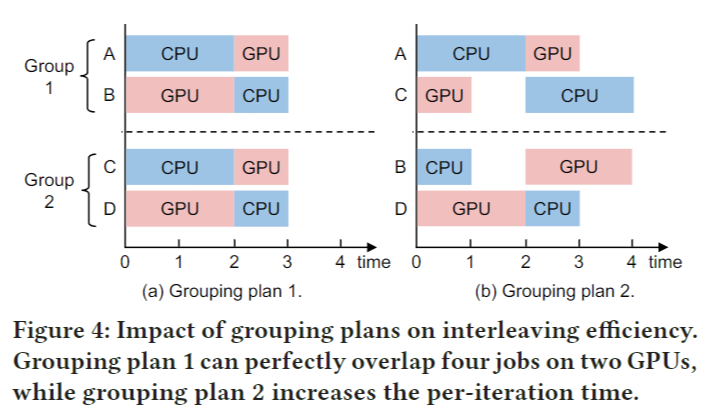
我们使用图 4 中四个作业(A、B、C 和 D)和两个资源类型(GPU 和 CPU)的示例来展示我们如何交错 DL 作业。该图显示了每个作业一次训练迭代的资源使用情况。为了便于说明,我们假设每次作业都使用一种资源类型。矩形的长度表示作业使用特定资源类型的长度。
我们改变不同工作的阶段,让工作相互交错,例如,在图4(a)组1中,作业A的CPU阶段与作业B的GPU阶段重叠,作业A的GPU阶段依次与作业B的CPU阶段重叠。我们在不同作业的重叠阶段之后添加了一个同步屏障。以图4(b)中的组1为例。C的CPU阶段等待到A的CPU阶段结束,而不是在自己的GPU阶段之后直接执行。避免两个作业同时使用一项资源的原因是处理速度可能会因干扰而受到显著影响。
Capturing resource interleaving efficiency.
当对两个作业进行分组时,我们需要一个度量来捕获资源交错效率。根据图4中的示例,能够完全重叠作业的资源使用的分组计划比不能重叠的分组计划要好。直观地说,更好的资源交错效率意味着更少的资源空闲时间。因此,我们定义了资源交错效率 𝛾 作为一些资源不空闲的时间的一部分。
我们定义$t_i^j$ 作为工作 $i$ 使用资源 $j$ 的时间 当我们交叉两个资源时迭代器T的持续时间 $T$ 为: \((1).T = max(t_0^0,t_1^1) + max(t_0^1,t_1^0)\) 对资源 $j$ 来说, 它在交叉了两个工作之后的空闲时间为 $T-t_0^j-$ $t_1^j$, 空闲比例为 $(T-t_0^j-t_1^j)/T$. 引入两种资源,他们平均空闲时间比例为 $\frac12\sum_{j=0}^1(T-t_0^j-t_1^j)/T.$ 请注意,我们采用空闲时间的平均分数来考虑所有资源类型。因此,资源交织效率 $\gamma$ (即资源不空闲的时间比例)是: \((2).\gamma=1-\frac12\sum_{j=0}^1\frac{T-t_0^j-t_1^j}T\) 我们使用图 4 中的示例来说明如何计算交错效率。对于对 A 和 B 进行分组,所有资源都被利用。CPU和GPU空闲时间的比例为0。因此,分组A和B的交织效率为1。对于分组A和C,持续使用CPU,CPU空闲时间的比例为0。GPU只利用了一半的时间,GPU空闲时间的比例为0.5。因此,分组A和C的交织效率为1-(0+0.5)/2=0.75。
Computing optimal grouping plans
给定n个作业,我们对作业进行分组,以便最大化整个分组计划的交织效率,以便更高的资源利用率以及更短的 JCT。
我们使用图 4 中的示例来说明分组问题。我们比较了两个分组计划。计划 1 将 A 与 B 分组,C 与 D 分组。A 密集使用 CPU,B 密集使用 GPU。如图 4(a) 所示,A 和 B 在不同资源上的资源使用可以完全重叠,对 A 和 B 进行分组可以充分利用这两种资源。同样,C 和 D 也可以通过相互交织来充分利用资源。相比之下,计划 2 将 A 与 C 分组,B 与 D 分组。A 和 C 都密集地使用 CPU,并稍微使用 GPU。如图 4(b) 所示,交错 A 和 C 不能完全使用这两种资源。当一个作业使用 CPU 时,GPU 处于空闲状态的时间很长。同样,分组 B 和 D 也达到了较低的资源利用率。
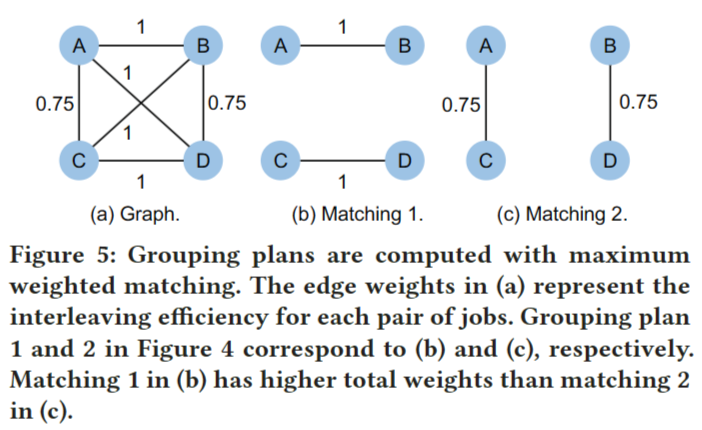
我们可以将这个问题转换为最大加权匹配问题。具体来说,我们构建了一个图 G (V , E),其中每个节点 v ∈ V 表示作业,每条边 (u, v) ∈ E 表示分组作业 u 和 v。我们使用等式 2 来计算交织效率 $\gamma_{u,v}$, 为对 u 和 v 进行分组,并分配 $\gamma_{u,v}$ 作为边的权重 (u, v)。图 G 的匹配 M 是一组边,其中没有两条边共享一个顶点。
| 分组计划对应于图的匹配。因此,找到最佳计划可以转化为找到图的最大加权匹配。最大加权匹配是图论中一个经过充分研究的问题。Blossom算法是一种多项式算法,可以在 $O( | V | ^3)$的时间复杂度下完成。对于图4中的示例,我们构建了一个具有图5(a)所示的四个节点的图。我们连接节点并计算交错效率作为每条边的权值。然后我们使用Blossom算法找到图的最大加权匹配,如图5(b)所示。图5(b)中的方案1对应图4(a)中的匹配,图5(c)中的方案2对应图4(b)中的匹配。计划1的权重总和高于计划2,说明资源效率更高。 |
Fusing multiple jobs.
可以将多个作业的同一阶段连接起来,并将这些作业融合为一个。例如,我们可以将图4中的作业A和作业C融合在一起,得到一个作业E,它首先使用4个CPU单位时间,然后使用2个GPU单位时间。假设作业F使用4个单位GPU时间和2个单位CPU时间。作业E和作业F的交织效率为1,如果不将作业A和作业C拼接在一起是无法达到的,而多作业的融合使得分组计划的搜索空间成倍增加,使得交织过程的控制和同步变得复杂。因此,我们避免融合多个作业,并为两种资源类型只分组两个作业。
4.2 Multi-GPU Multi-Resource Job Scheduling
Handling multiple resource types
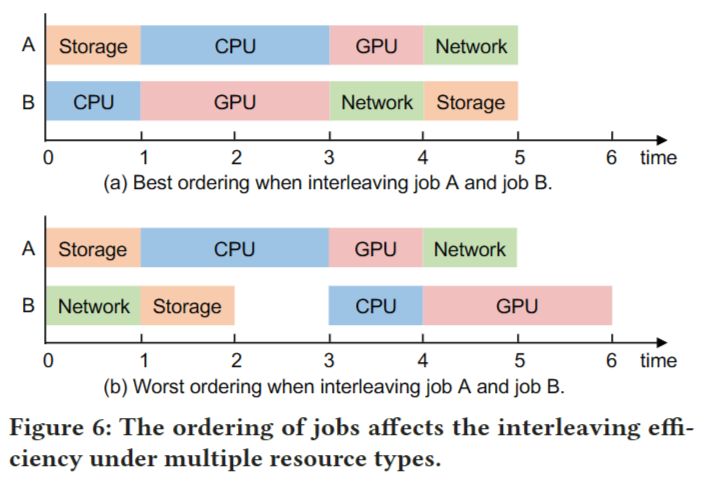
DL训练作业使用多种资源类型,例如 CPU、GPU、存储 IO 和网络 IO。从概念上讲,将调度算法从两种资源类型推广到多种资源类型需要解决两个问题。
第一个问题是估计交织效率。给定多个资源,交错两个作业有几个排序,不同的排序具有不同的交错效率。图 6 说明了这个问题,示例将两个作业与四种资源类型交错。对于每次迭代,作业 A 在 CPU 上花费两个时间单元,在所有其他资源类型上花费一个时间单元;作业 B 在 GPU 上花费两个时间单元,在所有其他资源类型上花费一个时间单元。图 6(a) 显示了完全与两个作业重叠的最佳排序。相比之下,图 6(b) 显示了两个作业不能完全重叠的更差排序。通过在执行中引入空闲时间,交织不必要地增加了每次迭代时间。图 6(b) 中的每次迭代时间长于图 6(a) 中的迭代时间。为了解决这个问题,我们枚举所有排序以找到最好的排序,然后计算交织效率。请注意,由于资源类型的数量很小(例如,DL 作业通常有四种资源类型),因此可以快速完成枚举。一旦确定了排序,一次迭代 T 的持续时间可以通过以下方式计算: \((3).T=\sum_{j=0}^{k-1}\max_{i=0}^{p-1}(t_i^{(i+j)\textit{mod k}} )\) 其中 k 是资源类型的数量,p 是一组里作业的数量。此外,我们可以将等式 2 扩展到 \((4).\gamma=1-\frac{1}{k}\sum_{j=0}^{k-1}\frac{T-\sum_{i=0}^{p-1}t_i^j}{T}\) 第二个问题是对给定多个资源的作业进行分组。与两种资源类型类似,我们避免将多个作业和打包最多为 k 个资源类型,以限制搜索空间并简化交织过程的控制和同步。尽管如此,当 k 大于2时,问题变得复杂,因为我们需要考虑在 k 维超图上匹配 k 作业,而不是法线图上的两个作业。形式上,对于 k 个资源类型,我们构建了一个 k 维超图 G(V,E)。每个节点 v∈V 代表一个作业;每个超边e ∈E 表示分组 k 个节点,e 的权重是分组相应 k 作业的交织效率。由于 n 个节点可以形成 $C_n^k$ 个不同的 k 节点组,因此 E 中有 $C_n^k$ 边。找到最佳分组计划被转换为在超图上找到最大加权匹配。这个问题在图理论中被称为最大加权均匀超图匹配,相当于最大权重独立集,因此是NP-hard。
1: // 𝑘 is the number of resource types
2: Initialize an empty graph 𝐺
3: // Add the first 𝑛 jobs to the graph
4: // These 𝑛 jobs can be fully grouped and they can fully utilize the cluster
5: 𝑗𝑜𝑏𝑠 ← 𝐽𝑜𝑏𝑄𝑢𝑒𝑢𝑒.𝑑𝑒𝑞𝑢𝑒𝑢𝑒 (𝑛)
6: for 𝑗𝑜𝑏 ∈ 𝑗𝑜𝑏𝑠 do
7: 𝐺 .𝑎𝑑𝑑𝑁𝑜𝑑𝑒 ( 𝑗𝑜𝑏)
8: // log 2 𝑘 rounds to group
9: for 𝑖 from 0 to 𝑙𝑜𝑔2𝑘 − 1 do
10: for each pair (𝑢, 𝑣) ∈ 𝐺 .𝑛𝑜𝑑𝑒𝑠 () do
11: 𝑤𝑒𝑖𝑔ℎ𝑡 ← 𝐶𝑜𝑚𝑝𝑢𝑡𝑒𝐼𝑛𝑡𝑒𝑟𝑙𝑒𝑎𝑣𝑖𝑛𝑔𝐸 𝑓 𝑓 𝑖𝑐𝑖𝑒𝑛𝑐𝑦(𝑢, 𝑣)
12: 𝐺 .𝑎𝑑𝑑𝐸𝑑𝑔𝑒 (𝑢, 𝑣, 𝑤𝑒𝑖𝑔ℎ𝑡)
13: // Find best matching with Blossom algorithm
14: 𝑀 ← 𝐺 .𝐶𝑜𝑚𝑝𝑢𝑡𝑒𝑀𝑎𝑥𝑖𝑚𝑢𝑚𝑊 𝑒𝑖𝑔ℎ𝑡𝑒𝑑𝑀𝑎𝑡𝑐ℎ𝑖𝑛𝑔 ()
15: // Each pair in 𝑀 forms an interleaving group
16: for each pair (𝑢, 𝑣) ∈ 𝑀 do
17: 𝑤 ← 𝑀𝑒𝑟𝑔𝑒𝑁𝑜𝑑𝑒 (𝑢, 𝑣)
18: 𝐺 .𝑟𝑒𝑚𝑜𝑣𝑒𝑁𝑜𝑑𝑒(𝑢)
19: 𝐺 .𝑟𝑒𝑚𝑜𝑣𝑒𝑁𝑜𝑑𝑒(𝑣)
20: 𝐺 .𝑎𝑑𝑑𝑁𝑜𝑑𝑒 (𝑤)
我们设计了一种多轮启发式算法来处理多种资源类型的一般情况,基于处理两种资源类型的见解。主要思想是将匹配过程分成多轮,每一轮使用 Blossom 算法来分组工作。在每轮结束时,Blossom 算法找到的匹配中的每一对节点合并为一个节点,并被馈送到下一轮以匹配其他节点。Algorithm 1 显示了算法的伪代码。一开始,它从队列中选择 n 个作业,以便这些工作可以形成充分利用集群的 k-job 组,并将作业放入图中(第 1-7 行)。我们在开始时添加所有潜在的作业以实现更好的匹配。然后在每次迭代中,它在每对节点之间添加一条边(第 10-12 行)。边权重是交织效率(第 11 行)。它使用 Blossom 算法来找到图的最大加权匹配(第 13-14 行)。对于匹配中的每一对,作业被分组,它们的节点合并到一个节点中,以便在下一次迭代中进行匹配(第 15-20 行)。由于每次迭代中一个组中的作业数量翻倍,因此对 $log_2k$ 次迭代执行。我们的多轮分组算法的时间复杂度为$O(n^3log_2k)$。
Handling multi-GPU jobs
分布式训练通常用于训练大型模型。在数据并行训练中,每个worker在本地训练模型的副本,并在每次迭代结束时执行模型同步。这意味着每个worker都可以独立使用自己的 CPU、GPU 和存储资源,但在使用网络资源同步模型时必须相互协调。由于需要作业内同步,作业的速度取决于其最慢的worker。例如,如图7所示,GPU 2上作业A的worker必须与GPU 1上的worker同步,这导致GPU 2上存在一个单元空闲时间。另一方面,多资源交错引入了作业之间的新依赖关系。当一组作业相互交织以共享相同的资源集时,作业的速度取决于组中其他作业的速度和资源使用模式。对于分布式训练作业,每个工作人员可以在不同的 GPU 上与一组不同的作业交织在一起。在这个场景,作业间交错与作业内同步交互,这带来了额外的开销。图 7 中的具体示例表明,在 GPU 1 上,作业 A 必须在使用 GPU 与作业 B 交错后等待一个时间单元使用网络,在 GPU 2 上,作业 C 也必须等待作业 A。
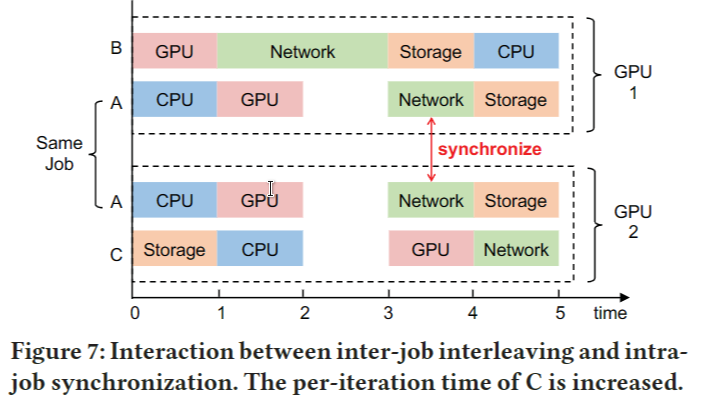
作业间交错和作业内同步都引入了依赖关系,作业的速度由最慢的worker决定。重要的是,这个问题具有级联效应。具体来说,由于作业内同步,由于作业间交错而导致的作业减速会影响其所有工作人员。然后,由于作业间交错,减速进一步传播到共享第一个作业的任何worker的工作。为了避免级联效应,Muri 将多 GPU 作业划分为不同的桶。同一桶中的作业使用相同数量的 GPU。Muri 应用多轮分组算法将作业分组到同一个桶中,即只有具有相同 GPU 要求的组作业。
Optimizing for average JCT
作业被提交给调度程序,并被缓冲在待调度的作业队列中。多资源分组算法计算作业分组计划。即使资源是共享的,队列所包含的作业数量也可能超过集群上调度的作业数量。因此,调度器需要决定应该运行哪个作业子集。由于多资源分组本质上提高了makespan,我们还针对另一个常见指标——平均JCT进行了优化。像FIFO这样的简单策略有排队头阻塞(head-of-line, HOL),其中小作业被队列前面的大作业阻塞,导致平均JCT长。对于深度学习训练工作量,当工作持续时间已知和未知时,SRSF和2D-LAS分别可以有效地最小化平均JCT[15]。Muri将SRSF和2D-LAS与多资源交错集成在一起,以提高资源利用率并最小化平均JCT。
具体来说,Muri为每个作业分配优先级,并根据优先级对队列中的作业进行排序。在调度作业时,Muri将作业从头部解队列,并使用多资源分组算法对解队列的作业进行分组。对于每一组工作,Muri将它们穿插在一起共享资源。每个作业的优先级由SRSF或2D-LAS根据作业持续时间是否已知来计算。形式上,让 $P_i$ 是作业 $i$ 的优先级。$P_j$ 的较低值意味着更高的优先级。当作业持续时间已知时,让 $r_i$ 是作业 $i$ 的剩余时间,而 $g_i$ 是 $i$ 使用的 GPU 的数量。SRSF 将作业 $i$ 的优先级计算为 $p_i=r_ig_i$。当作业持续时间未知时,让 $a_i$ 是作业 $i$ 已经运行的时间。2D-LAS 将作业 $i$ 的优先级计算为 $p_i=a_ig_i$。注意,SRTF和LAS考虑的是作业只有单个 GPU 执行,仅使用 $r_i$ 和 $a_i$ 作为优先级。SRSF 和 2D-LAS 通过考虑每个作业使用的 GPU 数量来扩展它们,更适合 DL 训练工作负载。
Handling multi-resource usage in practice
在实践中,不同资源类型的使用是重叠的。在估计交错效率时,我们将每个作业的每种资源类型的使用归一化到其峰值。对于每个时间点,我们将资源使用率最高的资源类型视为作业使用的资源类型。如果作业的资源使用低于阈值,我们还将其过滤为零。有了这个,我们估计每个资源类型的持续时间。
Ⅴ. Implementation
构建了一个总共有7000行代码的Muri原型,并将其与PyTorch集成[2]。原型遵循图3中的体系结构,其中有两个主要组件:Muri调度器和Muri执行器。Muri调度器由资源分析器、作业调度器和工人监视器三个模块组成。
5.1 Muri scheduler
调度程序以固定的时间间隔运行调度算法,以减少抢占和重新启动的开销。时间间隔是一个可配置的参数,我们使用与之前工作相同的值,即6分钟。它生成分组和安置计划,并根据计划调度作业。根据每个作业的资源概况和调度算法生成分组计划。如果一个模型是第一次提交的,那么调度器将使用一个执行器执行数十次迭代,以获得每种资源类型在一次迭代中的平均时间。否则,作业调度器将使用记录的资源配置文件。我们遵循通常的做法,将DL作业所需的GPU数量设置为2的幂。该布局方案根据作业所需的GPU数量从小开始分配,避免了作业的碎片化,减少了作业占用的节点数量。当生成分组和放置计划时,调度器将根据计划终止旧作业并启动新作业。工作监视器监视每台机器的资源信息,例如,GPU利用率,CPU利用率和磁盘IO速度。由于硬件限制,不监控网络IO速度。此外,工作者监视器跟踪每个作业以处理事件,例如启动、终止和作业完成。当工作监视器接收到调度器的查询时,它报告从执行器收集的信息。
5.2 Muri executor
每个执行程序根据调度器的分组计划执行DL作业。我们使用PyTorch作为深度学习框架在每台机器上运行深度学习训练作业,使用Horovod进行分布式训练。为了交叉不同的阶段,由于两个原因,我们将DL作业合并到一个进程和一个CUDA上下文。首先,我们可以使用PyTorch和CUDA的异步操作和同步操作来控制一个进程中的各个阶段,这些操作具有较低的协调开销。其次,一个CUDA上下文避免了上下文切换的开销。我们将重叠过程集成为一个Python库。用户只需要在模型训练代码中标注数据加载、计算和梯度同步。这部分也可以直接集成到PyTorch中,以避免对训练代码的更改,我们将这些更改留到将来的工作。执行程序记录执行迭代的次数和迭代的平均时间,并将这些信息提供给工作监视器。当资源分析器指示执行器对作业进行分析时,它会启动作业并通过PyTorch profiler测量迭代的每个阶段的时间,例如加载数据,预处理数据,向前和向后传播以及通信。我们将测量的时间视为近似的资源时间,因为每个阶段主要使用一种资源类型,例如:,前向和后向传播主要使用GPU。经过几次试运行后,将时间报告给资源分析器。与漫长的训练过程相比,分析开销可以忽略不计。具体来说,分析器执行一个模型只需要几十次迭代就可以获得稳定的分析结果,而在评估中使用的实际跟踪中,训练过程平均需要~ 136,482次迭代。此外,执行者在培训期间协助处理故障。当发生故障时,执行者将错误信息报告给工人监视器并终止培训过程。相关的DL作业将被推回作业队列。
5.3 Scalability
集中式调度器可以在几秒钟内为1,000个作业生成分组计划,这与调度间隔相比可以忽略不计,并且不是系统瓶颈。执行者运行由调度器指示的培训工作。Muri没有引入新的可扩展性挑战,其架构与现有的DL集群调度器一致。
Ⅵ. Evaluation
我们首先将Muri与最先进的DL调度器在具有64个GPU的测试台上进行比较。结果表明,Muri使平均JCT提高2.03 ~ 3.56倍,最大完工时间提高1.47 ~ 1.59倍,尾部JCT提高2.54 ~ 3.82倍。然后,我们通过模拟在更大的Microsoft Philly跟踪上对Muri进行了评估,结果表明Muri将平均JCT提高了1.13 - 6.15倍,最大跨度提高了1.00 - 1.65倍,尾部JCT提高了1.21 - 5.37倍。我们还对Muri的设计选择进行了评估。
6.1 Experiment Setup
Testbed:使用由8台机器和64个gpu组成的集群进行实验。每台机器配备8个NVIDIA Tesla V100 gpu, 2个Intel Xeon Platinum 8260 cpu, 256GB内存和一个Mellanox CX-5单端口网卡。这些机器通过NCCL2和RDMA (RoCEv2)进行通信。DL训练工作运行PyTorch v1.8.1与CUDA 11.1。
Workloads:我们使用来自Microsoft[19]的公开真实跟踪,并根据虚拟集群ID拆分跟踪。我们用用于模拟的四个跟踪,其作业编号从992到5755不等。对于试验台实验,我们选择包含400个作业的最繁忙间隔。我们从跟踪中使用每个DL作业的提交时间、持续时间和GPU数量。对于不知道持续时间的调度器,如Tiresias、AntMan、Themis、Muri-L。由于每个作业的深度学习模型不包括在轨迹中,我们遵循常见的做法,从表3中列出的八个流行的深度学习模型中随机选择深度学习模型。表3列出了每个GPU的批处理大小。训练迭代的次数是根据任务的持续时间和一次迭代的平均时间来计算的。DL模型在PyTorch中使用通用配置实现,这些配置已经应用了作业内部流水线来重叠每个作业中不同资源类型的使用。我们在§6.4中展示了Muri对工作负载分布的敏感性。
Simulator:我们实现了一个模拟器来评估大跟踪和不同配置的调度器。模拟器是基于tiressias和Gavel的开源代码实现的。我们在真实的测试平台上分析了每种资源类型和一次迭代的持续时间。仿真指标与试验台实验指标的差异在3%以内,表明该模拟器具有较高的保真度。
Baselines:我们的评估涵盖了作业持续时间已知和未知的两种情况。Muri- s和Muri- l分别代表以SRSF和2D-LAS为优先级的Muri。当作业持续时间已知时,我们将Muri-S与SRTF和SRSF进行比较[15]。当作业持续时间未知时,我们将MuriL与Tiresias斯[15]、蚁人[45]和Themis[25]进行比较。对于测试平台实验,我们将调度间隔设置为6分钟,以最小化抢占和重新启动的开销。对于Tiresias[15],我们在开源代码中使用默认的超参数。因为AntMan[45]没有开源它的调度器部分,我们只在模拟中比较它。
现有的多资源调度器[12 -14]大多是针对大数据工作负载设计的,利用每种资源类型的峰值需求进行空间共享。对于大多数DL训练任务,GPU需求峰值接近1,这意味着空间共享几乎没有共享机会。因此,现有的多资源调度程序在调度DL训练作业以优化平均JCT时退化为SRTF或其变体。
在对Muri(§6.4)的分析中,我们改变了Muri的配置来显示每个组件的效率。为了简单起见,我们使用k-job group来表示具有k个作业的组。
Metrics:在真实的集群实验中,我们测量了平均JCT、makespan、尾部JCT、队列长度、阻塞索引和资源利用率。平均JCT和makespan是反映调度器工作效率和资源效率的两个常用指标[36]。聚类中的尾部JCT评估公平性[18]。队列长度是集群中待处理作业的数量,反映集群的繁忙程度[18]。阻塞指数是待处理作业的待处理时间与剩余时间的平均比率,隐含地显示了避免作业饥饿的能力[18]。资源利用率表示如何利用资源。
6.2 Muri in Testbed Experiments
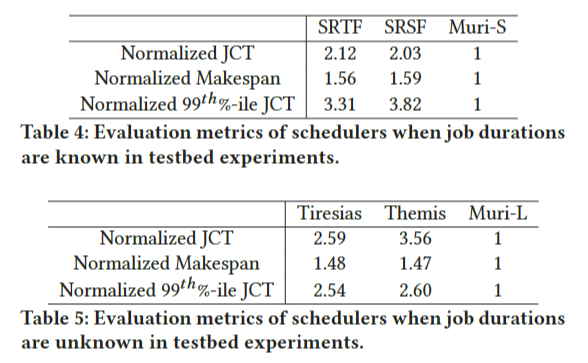
表4和表5显示了64 GPU集群上每个调度器的平均JCT、makespan和尾JCT(第99百分位数)。由于一个轨迹需要数十天的时间,我们在实验中采用快进法作为前期工作[44]。具体地说,我们执行多个迭代来度量平均迭代时间,并在没有调度事件发生时跳过迭代。我们确认快进结果近似于2小时跟踪的全面执行结果。误差率低于2%。
Overall performance on real cluster
从表4可以看出,Muri-S与SRTF相比,平均JCT提高了2倍以上,最大完工时间提高了1.5倍以上,尾部JCT提高了3.3倍以上。表5显示,在作业持续时间未知的情况下,与Tiresias和Themis相比,Muri-S的平均JCT提高了2.5倍以上,最大作业时间提高了1.4倍以上,尾JCT提高了2.5倍以上。这些结果表明,Muri可以同时提高作业绩效和集群效率。从理论上讲,Muri的完工时间可以比基线高出4×shorter。然而,在我们的评估中,有两个主要原因导致了较低的加速。首先,即使一个组有四个工作,也很难实现4倍的加速。虽然一个阶段主要占用一种资源类型,但该阶段仍可能使用其他资源类型。因此,不同阶段之间的资源争用降低了处理速度,导致较小的加速。其次,当考虑到整个跟踪时,加速会进一步降低,因为集群并不总是足够繁忙,调度程序无法为每个GPU分组四个适当的作业。Muri的平均JCT和尾JCT更好,因为作业可以在Muri中比基线更早地执行。
Detailed metrics to show the benefits of Muri
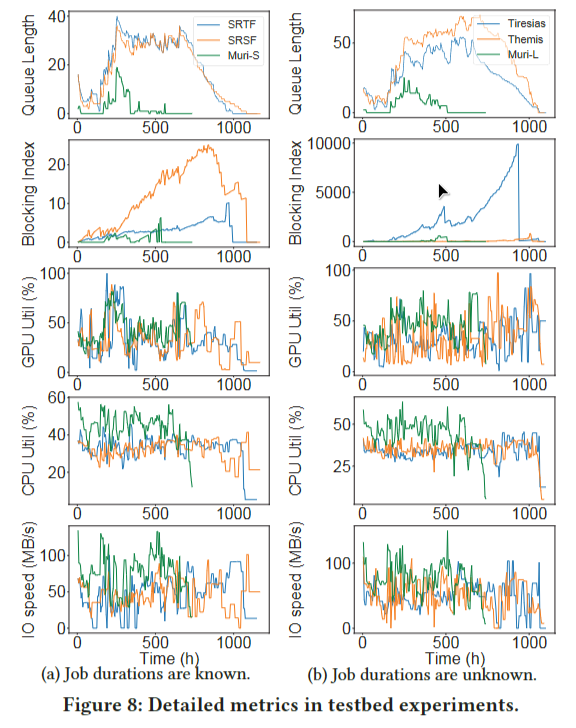
图8显示了队列长度、阻塞索引以及IO、CPU和GPU资源的利用率统计信息。队列长度反映集群的繁忙程度。Muri可以显著缓解繁忙,因为它同时运行更多的DL作业。阻塞指数反映了工作效率和避免饥饿的能力。当使用旨在降低平均JCT的调度器时,可能会发生严重的饥饿[18]。木鲤的阻断指数较低,说明其具有天然的抗饥饿能力。原因是Muri同时执行更多的任务,从而帮助缓解饥饿。资源利用曲线表明,Muri能够更有效地利用资源。这些结果验证了§4中的解释,即Muri改进的一个关键来源是通过交叉不同工作的训练阶段来利用空闲资源的能力。
6.3 Muri in Trace-Driven Simulations
我们通过跟踪驱动模拟来评估Muri在各种工作负载和配置下的性能。图9和图10进行了比较Muri与SRTF、SRSF、Tiresias、Themis和AntMan的平均JCT、makespan和尾JCT(第99百分位)。仿真中使用了两种类型的迹线。跟踪1 -4是原始的Microsoft Philly跟踪,而跟踪1 ‘ -4 ‘是跟踪1 -4的变体,通过在模拟开始时使所有作业可用(即,将所有作业的提交时间设置为0)。
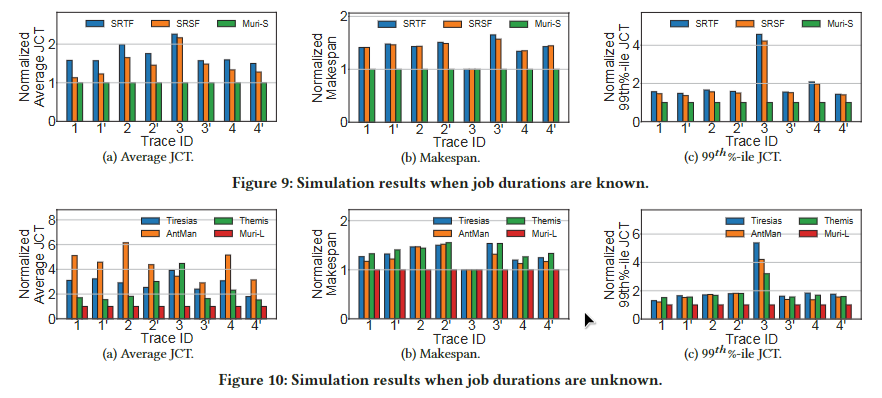
6.4 Muri improves performance on all traces
在作业持续时间已知的情况下,平均JCT的加速为1.13-2.26×,最大完工时间的加速为1-1.65×,尾JCT的加速为1.36-4.57×。作业持续时间未知时,平均JCT的加速为1.53 ~ 6.15倍,最大作业时间为1 ~ 1.55倍,尾JCT的加速为1.21 ~ 5.37倍。我们发现作业持续时间未知时,平均JCT的加速比作业持续时间已知时要高。原因是当作业持续时间未知时,决定应该首先调度哪些作业以降低平均JCT更具挑战性。结果,Tiresias和Themis的表现不如SRTF。由于Muri可以并发运行更多作业,因此选择要运行的正确作业集对它的影响较小,并且与Muri- s相比,Muri- l的性能略有下降。AntMan[45]是一个最先进的GPU共享调度程序。在某些情况下,AntMan的makespan和尾部JCT优于Tiresias和Themis,因为共享GPU可以同时运行多个作业。AntMan不能很好地工作于平均JCT,因为AntMan按照FIFO顺序调度DL作业,并且是非抢占的。对于跟踪3,Muri在最大时间跨度上没有加速,因为跟踪是轻负载的,并且在跟踪结束时提交的几个作业支配了整个跟踪的最终完成时间。此外,一些较长的DL训练作业是在trace 3开始时提交的,在基线中执行较晚,这导致尾部JCT差异很大。
6.5 Impact of load
我们通过将所有作业的提交时间设置为0来评估具有较高负载的调度器,即跟踪1 ‘ - 4 ‘的结果。在所有情况下,当提交时间为0时,makespan的加速都高于原始跟踪的加速,这反映了负载的影响。原因是当所有的作业都在时间0时,资源争用程度较高,这为多资源交错提供了更多的机会,因此Muri可以提供更高的改进。
6.4 Analysis of Muri
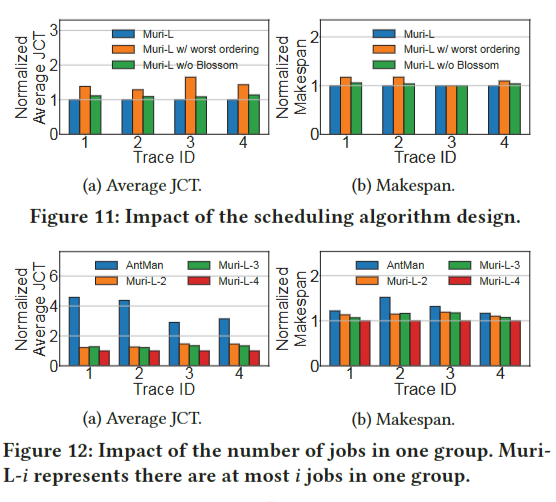
Impact of the scheduling algorithm design
Muri调度算法寻找一组作业交错的最佳排序,并使用Blossom算法决定如何对作业进行分组。为了展示这两种设计选择的好处,我们将Muri-L与两种变体进行比较,即排序最差的Muri-L和没有Blossom的Muri-L。最差排序的Muri-L将最差执行顺序的作业穿插在一起,以更好地显示执行顺序的影响。没有Blossom的Muri-L按照优先级降序排列GPU需求相同的DL作业,而不是使用基于Blossom的多轮分组算法。图11比较了Muri-L和两个变体的平均JCT和最长时间。首先,最差排序的Muri-L的两个指标都比Muri-L的指标差,这证实了一个组中工作排序的重要性。其次,没有Blossom的Muri-L的平均JCT比Muri-L长14%,makespan比Muri-L长6%,证明了基于Blossom的多轮分组算法的有效性。
Impact of the number of jobs in one group
我们将一组中的最大作业数从2个更改为4个,并将其性能与最先进的GPU共享调度器AntMan进行比较。为了更好地说明一组作业数量的影响,我们将所有DL作业的提交时间设置为0。图12中的结果显示,无论一组中有多少个工作,Muri的表现都优于AntMan。正如预期的那样,平均JCT和makespan与组内作业数量呈负相关,表明了多资源多作业共享的有效性。此外,2作业分组的改进接近甚至高于3作业分组,这表明分组更多的作业来共享同一组资源可能会带来更多的开销。根据我们在试验台实验中的分析结果,3作业分组的开销可能会超过分组的好处与2作业分组相比,更多的作业,而4作业分组带来了足够的交叉优势,可以改善这两个指标。
Impact of workload distributions.
表3中的工作负载包含了存储、网络、GPU和CPU四种不同资源类型上的作业瓶颈。在这个实验中,我们改变了作业类型的数量,从一个(即,只包含在一种类型的资源上瓶颈的作业)到四个(即表3中的工作负载)。图13显示了在已知(未知)作业持续时间下,Muri-S (Muri-L)与SRTF (Tiresias)的速度提升。当只有一种作业类型时,Muri的执行与SRTF和Tiresias类似。由于共享机会有限,它略好一些。加速随着工作类型的增加而增加。只有两种工作类型的Muri已经是SRTF的1.42倍和tiressias的1.49倍。Muri有4种工种,SRTF为2.26倍,Tiresias为3.92倍。
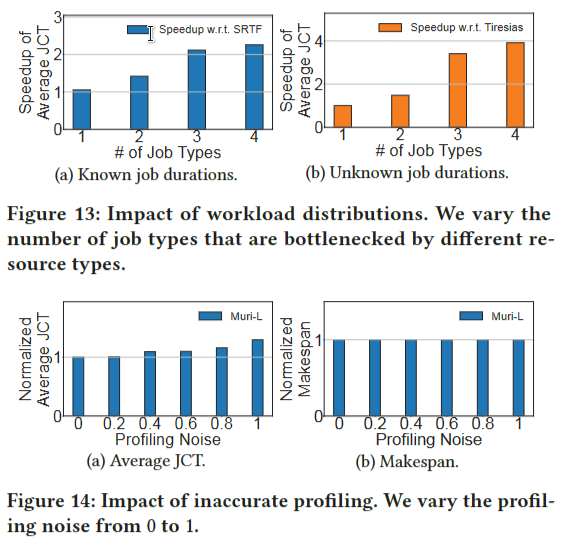
Impact of inaccurate profiling
在实践中,与实际执行时间相比,Muri的分析器所分析的每个阶段的持续时间可能是不准确的。这种不准确性主要来自两个方面。首先,由于硬件和软件条件的不同,每次的实际执行时间不同。其次,分析器有一些噪声并返回不准确的分析结果。为了评估不准确分析的影响,我们人为地改变分析噪声?? 从0到1。具体来说,Muri得到每个阶段的持续时间,即实际执行持续时间乘以[1−?? 1 + ?? ]。图14显示了标准化到没有分析噪声的平均JCT和makespan,即?? = 0。归一化平均JCT从1×增加到1.3×,表明不准确的剖面影响了Muri的性能。然而,在实践中,分析噪声通常在0.2以下,这使得平均JCT只增加了不到1%,如图14所示。就标准化的最大时间跨度而言,它仍然存在1×under各种分析噪声,主要是因为负载较轻的跟踪和几个较长的DL作业。因此,在实际应用中,不准确的轮廓对Muri的性能影响不大。
Ⅶ. Conclusion
我们提出了Muri,一个利用多资源交错来提高集群和作业效率的DL集群调度器。Muri利用DL作业的分阶段迭代计算模式。提出了反映交织效应的交织效率公式,并将调度问题转化为匹配问题。为了最大限度地提高交织效率,我们设计了一种基于Blossom算法的多资源多作业打包调度算法。无论作业持续时间是否已知,Muri的性能都优于现有的DL集群调度器。