Ⅰ. Abstract
3D shape completion from point clouds is a challenging task, especially from scans of real-world objects. Considering the paucity of 3D shape ground truths for real scans, existing works mainly focus on benchmarking this task on synthetic data, e.g. 3D computer-aided design models. However, the domain gap between synthetic and real data limits the generalizability of these methods. Thus, we propose a new task, SCoDA, for the domain adaptation of real scan shape completion from synthetic data. A new dataset, ScanSalon, is contributed with a bunch of elaborate 3D models created by skillful artists according to scans. To address this new task, we propose a novel cross-domain feature fusion method for knowledge transfer and a novel volume-consistent self-training framework for robust learning from real data. Extensive experiments prove our method is effective to bring an improvement of 6%∼7% mIoU.
文章认为从真实世界扫描到的的三维形状补全是一个很有挑战性的任务,目前的工作仅仅集中在对合成数据进行基准测试(如从CAD模型中模拟扫描过程获取的点云),但是真实扫描数据和合成数据的差异性限制了这些工作的泛化性能;因此文章提出了一个新的任务:SCoDa(Domain Adaptive ShapeCompletion),即对从合成数据出发对真实扫描形状进行补全的域自适应。文章提出了一个新的数据集:ScanSalon(realScans with Shape manual annotations),是人工从扫描的数据中创造的3D模型;又提出了一种新的跨域特征融合方法用于知识转移,以及一种新的体积一致的自训练框架,用于从真实数据中进行鲁棒学习。
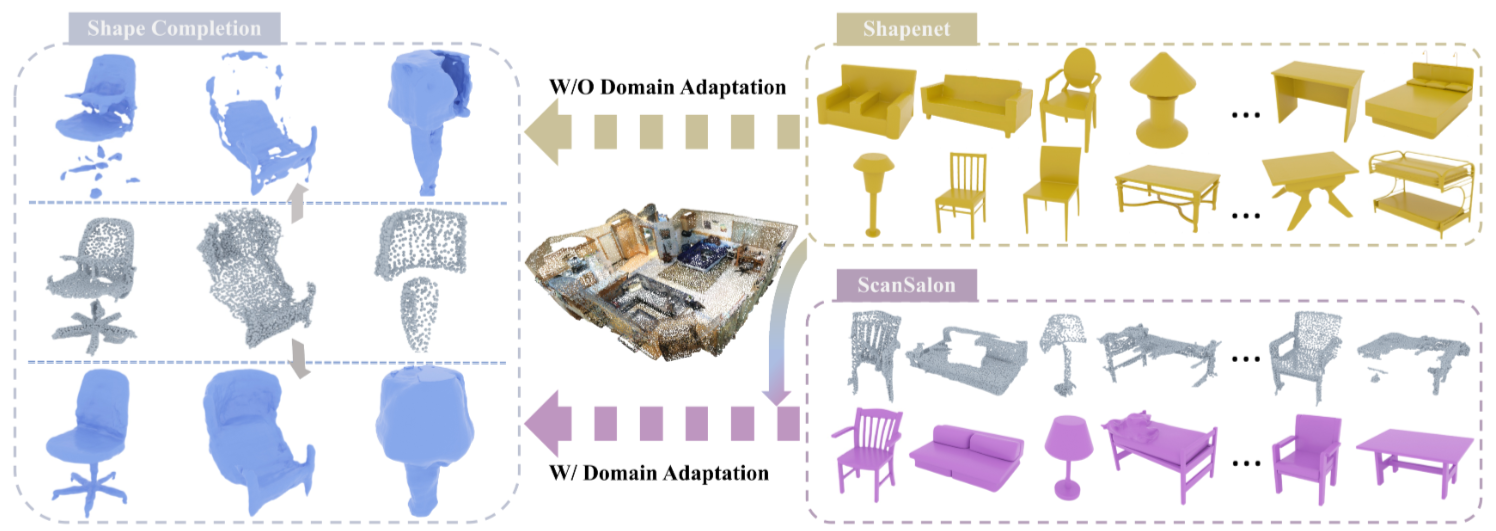 Figure 1. The proposed task SCoDA aims to transfer the knowledge in the synthetic domain to the reconstruction of noisy and incomplete real scans. A dataset, ScanSalon, with paired real scans and 3D models is contributed.
Figure 1. The proposed task SCoDA aims to transfer the knowledge in the synthetic domain to the reconstruction of noisy and incomplete real scans. A dataset, ScanSalon, with paired real scans and 3D models is contributed.Ⅱ. Contributions
-
提出了一种新的任务 SCoDA,即真实扫描的域自适应形状补全;贡献了一个包含 800 个精细 3D 模型的数据集ScanSalon,并与真实扫描的 6 个类别一一对应。
-
设计了一种新的跨域特征融合模块(cross-domain feature fusion module),将合成域和实域学习到的全局形状和局部模式的知识结合起来。这种特征融合方式可能给二维域适应领域(2D domain adaption field)的工作带来灵感。
For an effective transfer, we observe that although the local patterns of real scans (e.g., noise, sparsity, and incompleteness) are distinct from the simulated synthetic ones, the global topology or structure in a same category is usually similar between the synthetic and real data, for example, a chair from either the synthetic or real domain usually consists of a seat, a backrest, legs, etc. (see Fig. 1). In other words, the global topology is more likely to be domain invariant, while the local patterns are more likely to be domain specific.
- 提出了一种体积一致的自训练框架(volume-consistent self-training framework),以提高形状补全对真实扫描复杂不完整性的鲁棒性。
- 为基于ScanSalon的SCoDA任务构建了多种评估方法的基准;大量的实验也证明了所提方法的优越性。
Ⅲ. Method
IF-Nets 是一种有前途的重建方法,本文就是基于IF-Nets进行的改进。我们的方法首先通过提出一种新的跨域特征融合模块来改进表示学习,该模块旨在将标签丰富的合成域中学习到的全局级对象形状的知识转移到真实域中。其次,为了在真实数据中耗尽特定领域的信息,针对特定的形状完成任务提出了一种新的体积一致的自训练方法。
3.1. Implicit Feature Networks
我们首先介绍IF-Nets[Implicit Functions in Feature Space for 3D Shape Reconstruction and Completion]作为我们的重建框架。IF-Net 由用于多尺度特征提取的 3D 卷积神经网络编码器 $g(\cdot)$ 和用于隐式形状解码的多层感知器组成。
给出一个点云样本 $P,$ 首先将他转换为一个体素的表示$\textbf{X}\in:\mathbb{R}^{\boldsymbol{N}\times\boldsymbol{N}\times\boldsymbol{N}}$ ,其中 $\begin{aligned}N&\in:\mathbb{N}\end{aligned}$ 是输入空间的分辨率。 $\text{X}$ 被送入一个L层的感知机 $g(\cdot)$ 来生成多尺度的特征:
\[\{\mathbf{F}_{1},....,\mathbf{F}_{L}\}\]然后他们被上采样到相同的空间维度并沿着channel进行拼接来生成最终特征:
\[\mathbf{F}=\mathbf{concat}(\{\mathbf{upsample}(\mathbf{F}_{1}),...,\mathbf{upsample}(\mathbf{F}_{L})\})\] \[g(\mathbf{X})=\mathbf{F},\quad\mathbf{X}\in\mathbb{R}^{N\times N\times N},\quad\mathbf{F}\in\mathbb{R}^{d\times N\times N\times N}\]$\text{a}$ 是特征通道的数量它等于 $\mathbf{F}_{\boldsymbol{i}}$的通道数之和。注意到 $\text{H}$ 有一个与数据 $\text{X}$ 对齐的3D结构。 给定一个点查询 $\mathbf{p}\in\mathbb{R}^{3}$,这个点上的连续特征 $\mathbf{F}(\mathbf{p})$ 可以使用线性插值法从 $\text{F}$ 抽取。
然后,将点 p 处的编码输入逐点解码器 $f(\cdot)$ 以给出二进制预测,指示该点是否位于形状内部或外部:
\[f(\mathbf{F},\mathbf{p})=f(\mathbf{F}(\mathbf{p}))\mapsto\{0,1\}.\]给定根据ground truth形状网格预先计算的每个位置p的占用值 $o(\mathbf{p})\in{0,1}$ 使用二元交叉熵损失训练g和f:
\[\min L_{IF}=\text{BCE}\big(f(\mathbf{F},\mathbf{p}),\:o(\mathbf{p})\big).\]请注意,预测值也可以是连续符号距离值,如[DeepSDF: Learning Continuous Signed Distance Functions for Shape Representation]所示。
3.2. Cross-Domain Feature Fusion
原始IF-Net的训练需要ground truth形状来生成大量的occupancy labels来监督f(·)的输出,但大多数真实扫描都与ground truth不配对。因此,我们开发了一个跨域特征融合模块来很好地传递标签丰富的源域中的知识。我们利用源知识的想法源于一个重要的观察结果:尽管合成数据与真实扫描具有不同的局部模式,但特定类别的全局级知识(例如,公共结构和粗形状)可以在两个域中共享。此外,标签较少的目标数据可能足以学习丰富的局部级信息。另一方面,IF-Nets 通过利用局部表示进行形状补全,因此在不引入源域偏差的情况下提取高质量的局部级特征是很重要的。
为此,我们开发了一个用于知识转移的跨域特征融合模块(CDFF)。首先,两个形状编码器 gs(·) 和 gt(·) 用于源数据和目标数据的特征提取,分别生成 Fs 和 Ft。如上所述,Fs 包含丰富的全局信息,Ft 在提供特定领域的局部级表示方面更可靠。采用简单的线性组合将它们融合成 F: \(\mathbf{F}=\mathbf{w}\cdot\mathbf{F}_{s}+(1-\mathbf{w})\cdot\mathbf{F}_{t}\) 其中 w ∈ [0, 1] 是一个通道权重向量。为了更好地结合Fs和Ft的优点,w的计算考虑了两个方面:
- (i)利用Fs中的全局特征,将Ft用于局部特征(基于我们的观察)
- (ii)自适应学习w以保持灵活性。
自适应权重向量 w 计算如下: \(\mathbf{w}=\alpha\cdot h(\mathbf{F}_s\odot\mathbf{F}_t)+\mathbf{w}^0\) 其中 α ∈ R+ 是自适应性的比率,h(·) → [0, 1] 是输出层具有 sigmoid 激活的两层 MLP,⊙ 表示逐元素乘法的操作加上空间维度上的全局池化(返回维度为 d 的向量)。w0 ∈ [0, 1] 是一个常数权重向量,这意味着从我们的观察中得出的先验,其中每个值 w0i 简单地由线性映射定义,如下所示: \(w_i^0=\frac{l_i}{L+1},i\in\{1,2,\cdots,d\}\) 其中 li ∈ {1, 2, · · · , L} 表示第 i 个通道属于哪个层。通过这种方式,一个通道的更深层来自,该通道中 F 的计算越多依赖于 F,因为 IF-Nets 的更深层捕获了更多的全局信息。此外,对 w 应用裁剪操作将所有值限制为 [0, 1]。
3.3. Volume-Consistent Self-training
在目标域中形状基本事实很少的情况下,很难以有监督的方式学习丰富的信息。典型的方法是采用自监督学习从数据中学习。在SCoDA任务中,不完整性是阻碍形状完成质量的真实扫描的一个重要特征。因此,我们创建了两个视图扫描,它们具有不同的不完整程度,并鼓励模型对它们的体积占用率做出一致的隐式预测。这种体积一致的自我训练 (VCST) 使得模型面对各种不完整问题时保持鲁棒性,并将缺失的部分“想象”为补全问题。
具体来说,我们首先采用无监督聚类算法(例如 k-means 聚类)将点云划分为 K 个不同的部分(示例见图 2)。聚类操作仅基于点的空间位置,它粗略地将对象扫描分割成多个分量。使用预先计算的分区,可以通过从原始真实扫描中随机丢弃不同的点簇来生成两个视图 Xa 和 Xb,其中 K ≥ Ka > Kb。此外,我们还对两个视图进行了两次随机下采样,以创建不同的稀疏性。请注意,基于聚类的增强实际上是表面感知增强。与随机屏蔽一些空间体积的基于体积的方法相比,我们的增强策略在一定程度上意味着包含更多的对象部分知识(object-part knowledge)。
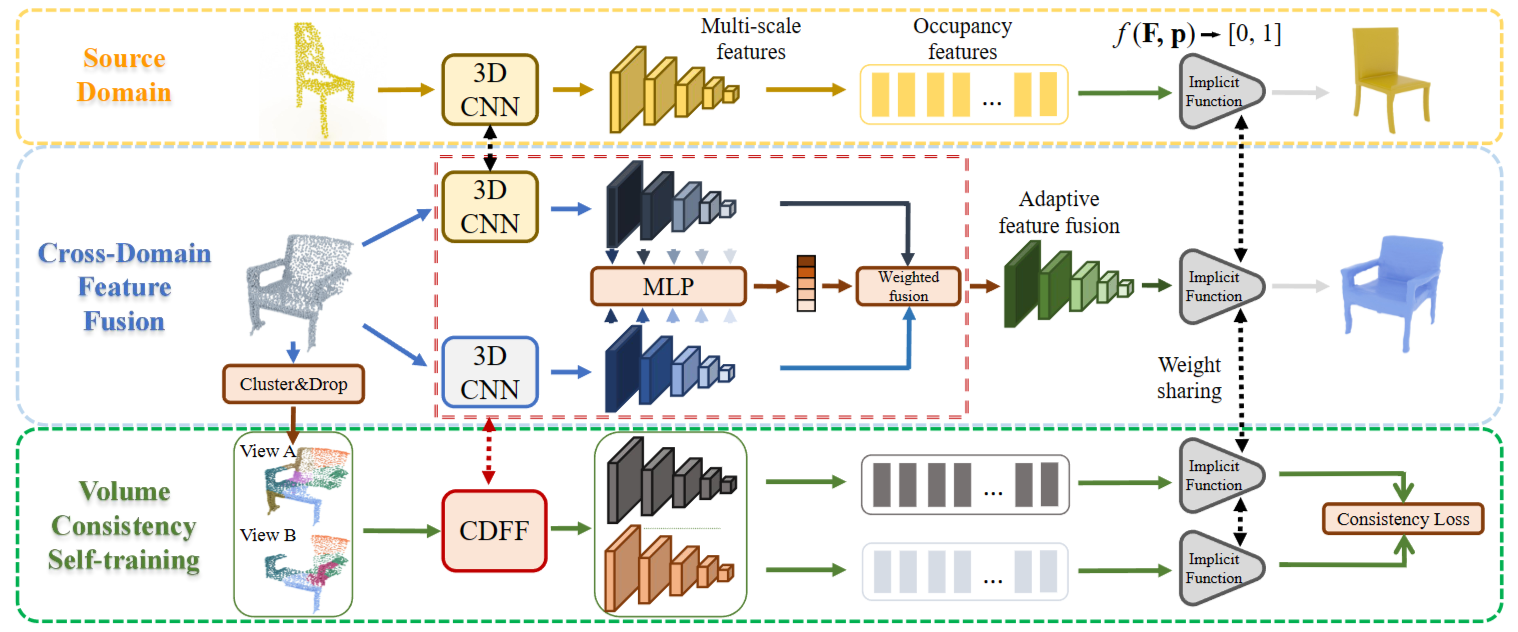
给定输入的两个视图,它们的特征由 g(·) 提取,然后由 f (·) 进行隐式预测: \(g(\mathbf{X}^v)=\mathbf{F}^v,v=A,B,\)
\[f(\mathbf{F}^v,\mathbf{p})\mapsto\{0,1\}.\]请注意, $\mathbf{F}^v$ 也可以通过我们的 CDFF 模块生成。在这里,我们简化了公式以更好地展示我们的 VCST。一致性约束应用于具有相同点查询 p 的 $f(\mathbf{F}^A,\mathbf{p})$ 和 f $f(\mathbf{F}^B,\mathbf{p})$ 的隐式预测:
\(minL_{CT}=\text{BCE}\big(f(\mathbf{F}^B,\mathbf{p}),\:f(\mathbf{F}^A,\mathbf{p})\big),\) 其中 $\mathrm{BCE}(\cdot,\cdot)$ 表示二元交叉熵损失。一致性目标可以看作是使用来自视图 A 的预测作为视图 B 的伪标签,因为$\mathbf{X}^B$ 的完整性比 $K_B<K_A.$ 的 $\mathbf{X}^A$ 差。由于目标数据的形状ground truth有限,隐式预测会出现噪声,使用噪声预测作为伪标签会误导训练。因此,执行阈值操作以掩盖对$f(\mathbf{F}^A,\mathbf{p})$低置信度的预测。整体损失函数是 $L_{IF}$ and $L_{CT}.$ 的总和。
Ⅳ. Dataset
Overview
所提出的ScanSalon数据集收集了7,644个真实扫描,其中800个对象配备了3D形状(artificial)ground truths。所有模型都或扫描来自 6 类对象,有 5 个常见的室内对象:椅子、桌子(或桌子)、沙发、床和灯,以及 1 个室外对象:汽车。详细统计数据列于表1中。在图4中,我们展示了ScanSalon中的一些真实扫描样本和相应的3D形状。更多可视化可以在补充材料中找到。
Data Collection
真实扫描分别从室内和室外物体的ScanNet和KITTI数据集两个数据集中收集。根据两个数据集提供的点级实例分割注释,从场景点云中提取对象扫描;然后将他们旋转并正则化到相同的姿势和尺度。这些数据也与ShapeNet数据库=中的模型对齐,后者提供了一堆合成模型作为源域。

Shape Annotation for Real Scans
两位熟练的艺术家参与了注释。除了真正的扫描之外,我们还为每次扫描提供了从不同角度拍摄的几张照片,这为提高模型质量提供了二维参考。图3所示的是一个简短的创作流程,艺术家需要根据扫描图和照片参考(见图4)来创作形状,克服扫描噪声的干扰,在照片参考差或不充分的情况下,通过丰富的经验来弥补不完整性。他们使用专业的3D软件Maya1来创建模型。制作一个3D模型平均需要0.5 ~ 1.0小时,800个模型的制作总共需要2.5个月。对于每个创建的模型,另外邀请8名检查员来验证他们的
- 与照片中真实物体的恢复程度
- 与给定扫描的匹配程度,并将缺陷反馈给艺术家进行进一步调整,直到任何检查员都没有发现缺陷。
考虑到ScanNet和KITTI扫描中物体的不可访问性,我们尽了最大的努力为这些扫描创建artificial ground truth。

Ⅴ. Experiments
omitted