Part Ⅰ: 代码练习
- MNIST 数据集分类:构建简单的CNN对 mnist 数据集进行分类。同时,还会在实验中学习池化与卷积操作的基本作用。
- CIFAR10 数据集分类:使用 CNN 对 CIFAR10 数据集进行分类,
- 使用 VGG16 对 CIFAR10 分类,
1.1 MNIST 数据集分类

DataLoader是用来加载数据集样本的类,创建DataLoader时需要指定数据集、transform、batch大小、以及是否随机读取样本。
Pytorch中已经内置好的许多数据集,使用的时候只需要使用datasets方法获取就可以了,但是如果是自己构建数据集,就需要重写Dataset类,并重写读取image与target的方法。
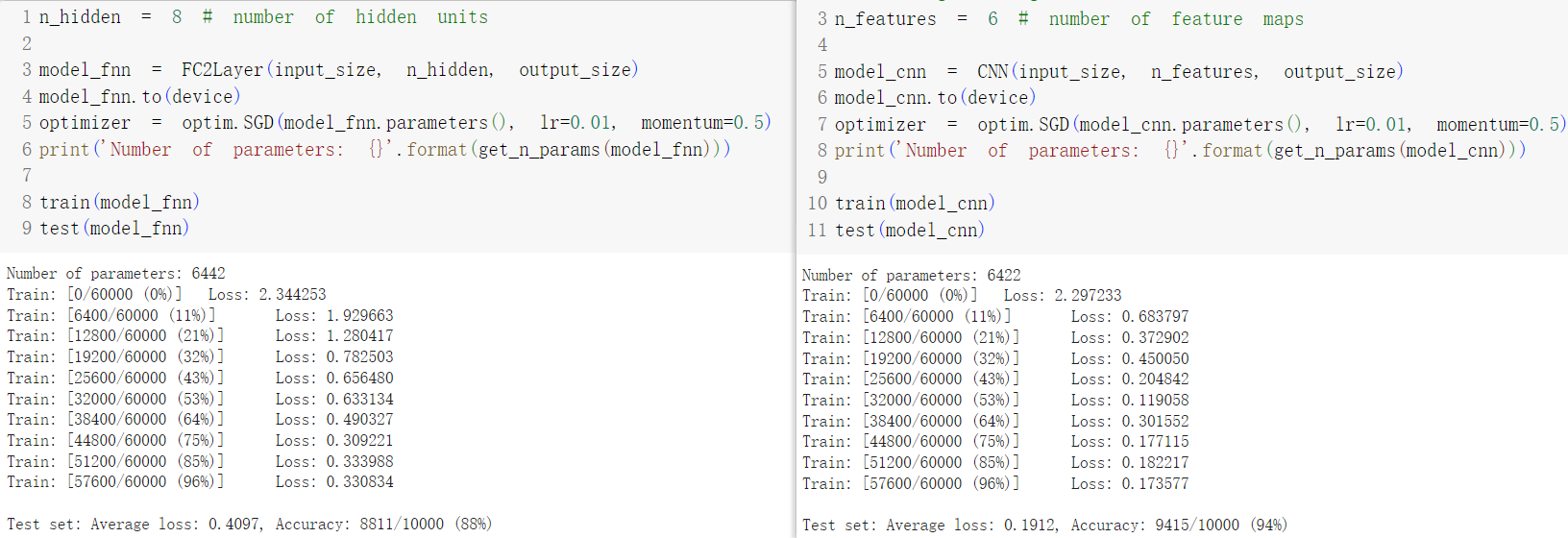
通过全连接神经网络和CNN的对比,我们发现CNN的Loss和Acc都比全连接神经网络要强,体现出CNN更为强大的泛化能力。

经过将样本像素打乱后,CNN的正确率大幅下降甚至不如全连接网络,因此我们知道CNN强大的泛化能力,是因为它能学习到图像相邻像素之间的关系,此乃空间上的联系。
这让我联想起RNN,RNN能够学习到得输入序列的前后顺序的关系,这是时间上的联系,如果将CNN与RNN结合在一起,岂不是空间与时间上的信息都能学习到?是不是能够处理视频信息呢?
1.2 CIFAR10 数据集分类
CIFAR10数据集不同于MINST,他的每个Class有更多的特征需要学习,我最直观的体现是在Colab上用T4跑的好慢,以前记得可以用V100呀,怎么不能用了,抠门。
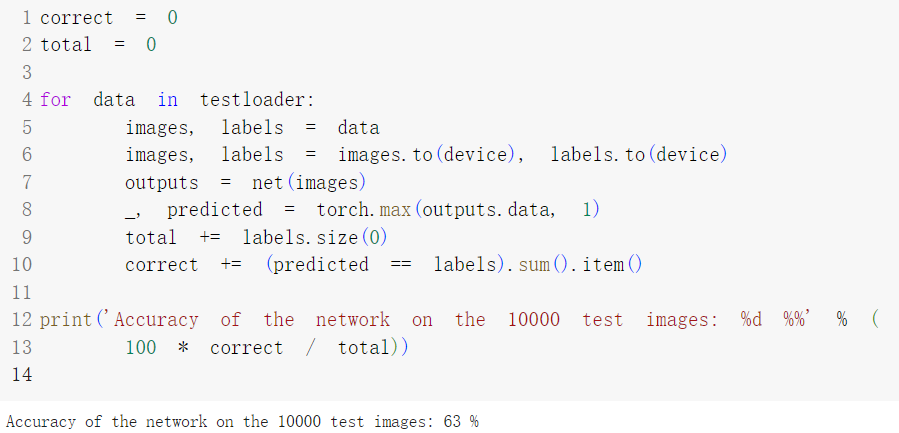
可以看到这个网络模型在CIFAR10上的准确率确实低,关于改进方法,练习中给出的代码只训练了10轮,我修改为训练50轮后再训练,但是正确率并没有提升。
Part Ⅱ : 问题总结
- dataloader 里面 shuffle 取不同值有什么区别?
- transform 里,取了不同值,这个有什么区别?
- epoch 和 batch 的区别?
- 1x1的卷积和 FC 有什么区别?主要起什么作用?
- residual leanring 为什么能够提升准确率?
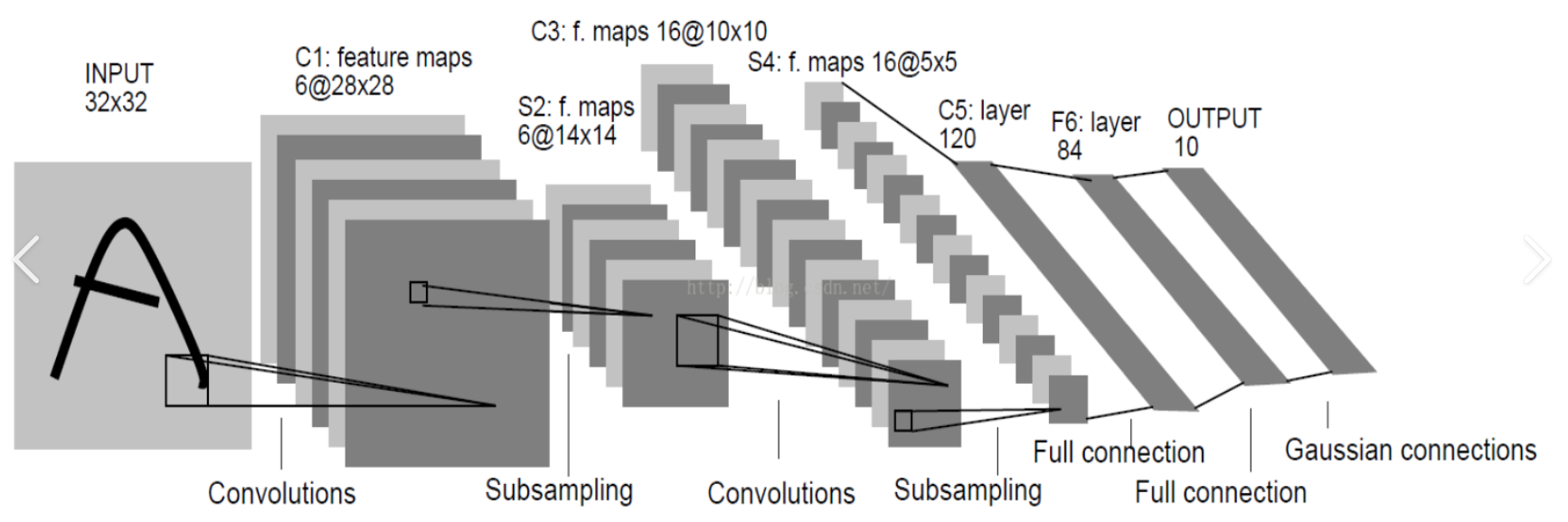
- 代码练习二里,网络和1989年 Lecun 提出的 LeNet 有什么区别?
- 代码练习二里,卷积以后feature map 尺寸会变小,如何应用 Residual Learning?
- 有什么方法可以进一步提升准确率?
2.1 Shuffle问题
DataLoader中的Shuffle从数据集中取样本是是否是随机取数据,True则表示随机读取样本,False表示顺序读取样本。
在我理解里,Shuffle的作用就是防止出现过拟合,因为如果每个Epoch的每一个batch的数据都一样,如果在样本情况比较极端的情况下容易陷入局部最优解的陷阱。
在网络上搜索到的答案是 “Shuffling helps break this order and ensures that the model doesn’t learn any unintended sequence patterns from the data. ” 差不多也印证了我的想法。
2.2 Transform问题
Transform是对样本进行图像处理的工具。Transform有旋转、剪裁、调整亮度、色相等功能,根据我们对样本的需要,我们可以选择几种处理样本;使用Tranform的最终目的也是防止出现过拟合,提升模型的泛化能力。
在此之外,Transform还有一重要的功能:数据增强;有时候我们自己构建的数据集样本量太少,训练出的模型泛化能力比较差,这个时候我们就可以用Transform的Randcrop、Rand***等方法处理样本,这样每一个Epoch读取的虽然是同一个图片,但是因为图片发生了随机的变化,这样的图片就相当于全新的样本,使得数据集发生了扩充。
最后我有一个问题,Transform的Normalize是干嘛的?
2.3 Epoch和Batch的区别
Epoch是指训练一轮,训练完数据集所有样本。Batch是指在一个Epoch里,每次从数据集中读取多少样本。
2.4 1x1的卷积等于FC?
首先1*1的卷积层在某种情况下相当于一个Fully connected。
全连接层的input一定是一个1 * 1 * n的特征图,因此在将特征图输入到全连接层之前需要进行Flatten处理,全连接层的作用是将卷积层获得的低级特征整合为高级特征,如将一个 1 * 1 * 4096的特征图连接为一个84 * 1 * 1的特征图。
1 * 1 * n的卷积input不一定非得是1 * 1 * n的特征图,如果Input是1 * 1 * n的特征图,那么卷积与FC没有任何区别;但是如果input的channel不是1的话,1*1的卷积可以起到降维的作用。
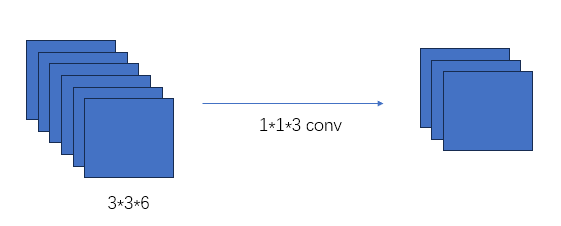
2.5 Residual Leanring 为什么能够提升准确率?
Residual即残差,是ResNet中提出的概念,具体实施在网络结构中是构建一个个残差块,在下层残差块输出中叠加上一个残差块的输出。
残差块的引入很好的解决了深度学习中梯度消失的问题,卷积层的引入使得深度网络的拟合能力大大提升,但是卷积层的特性使得在卷积采样时会丢弃图像的一些信息。引入残差的概念,可以很好的保存这些特征。避免出现梯度消失的现象。
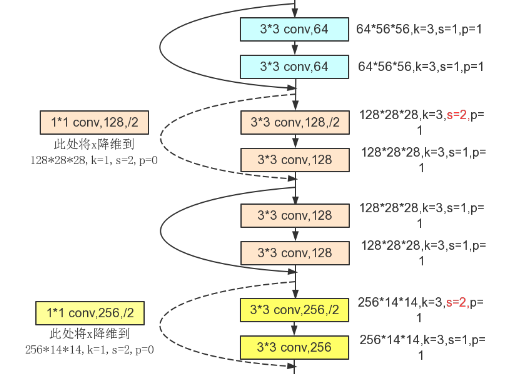
2.6 代码练习二的网络和 LeNet 有什么区别?
首先贴出两个网络的代码。
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(1, 6, 5), # in_channels, out_channels, kernel_size
nn.Sigmoid(),
nn.AveragePool2d(2, 2), # kernel_size, stride
nn.Conv2d(6, 16, 5),
nn.Sigmoid(),
nn.AveragePool2d(2, 2)
)
self.fc = nn.Sequential(
nn.Linear(16*4*4, 120),
nn.Sigmoid(),
nn.Linear(120, 84),
nn.Sigmoid(),
nn.Linear(84, 10)
)
def forward(self, img):
feature = self.conv(img)
output = self.fc(feature.view(img.shape[0], -1))
return output
- LeNet是平均池化,而练习中网络结构的是最大池化
- LeNet的激活函数是sigmoid,而练习中网络结构的是Relu。
2.7 ResNet中特征图大小不同如何相加
这部分论文里有说哦,我直接粘过来。
The identity shortcuts (Eqn.(1)) can be directly used when the input and output are of the same dimensions (solid line shortcuts in Fig. 3). When the dimensions increase (dotted line shortcuts in Fig. 3), we consider two options: (A) The shortcut still performs identity mapping, with extra zero entries padded for increasing dimensions. This option introduces no extra parameter; (B) The projection shortcut in Eqn.(2) is used to match dimensions (done by 1×1 convolutions). For both options, when the shortcuts go across feature maps of two sizes, they are performed with a stride of 2.
——“Deep Residual Learning for Image Recognition”
2.8 进一步提升准确率的方法
想要提高准确率在某种程度上就等于增强泛化能力、防止模型过拟合。
从增强泛化能力入手,我们可以:
- 使用质量更高的数据集,包括但不限于使用扩充数据集样本数量、清洗数据集样本等。
- 使用规模更大的网络模型,能够捕捉更多样本特征,但这同样意味着需要更多的算力进行训练。
从防止模型过拟合入手,即从正则化入手,我们可以:
- 增加正则化项,如Layer Normalize和Batch Nomalize。
- 添加Pooling层与Dropout层。
- 学习率递减,随着学习的增多减小学习的参数。
- 提前停止,设置一个验证集,当验证集上的错误率不在下降,就停止迭代。