Part Ⅰ: 代码练习
在谷歌 Colab 上完成 pytorch 代码练习中的 2.1 pytorch基础练习、2.2 螺旋数据分类,关键步骤截图,并附一些自己的想法和解读。
1.1 Pytorch基础练习
在接触Pytorch之前,我只知道Numpy是Python里一个非常强大的数据处理工具,特别是Numpy的ndarray,提供了非常多处理数组的函数;所以在用过Pytorch后我好奇的第一个问题就是,为什么放着现成的ndarray不用,而去使用一个名为Tensor的数据结构?搜索以后,所有的结果都指向一个答案:Tensor能使用GPU进行运算,而numpy不行,那么问题又来了,为什么呢?
numpy与tensor分别实现转置数列

显卡与挖矿:
在过去几年显卡挖矿的浪潮里,我了解了些关于所谓挖矿的一些原理:用显卡不断进行hash运算;这便是显卡最擅长的事情,用成千的流处理器单元并行计算加减乘除。这也许能解释为什么需要GPU进行运算,但是不能解释是如何让GPU进行运算的。
Cuda与TensorCore:
Nvidia显卡的CUDA工具套件一直是其对抗竞争对手AMD的一大利器,已经在AI加速运算领域处于绝对领先地位。很明显,了解CUDA是如何工作的就等于明白了Tensor使用GPU进行运算的真相。
自Volta架构起,Nvidia在其显卡中引入了Tensor Core这一特殊的Unit,使其单精度运算运算能力比上一世代提升了12倍,而其CUDA工具套件就是访问Tensor Core的api接口。这下终于真相大白:Tensor在其数据结构中实现了CUDA套件提供的API,所以其能够使用GPU进行运算。

1.2 螺旋数据分类
在生成螺旋数据部分,我认为最重要的是理解N/D/C/H在X和Y中的含义;X 为特征矩阵,它为样本集中的每个样本确定一个特征向量,因为在二维坐标系中所谓的特征无非是x轴坐标与y轴坐标,因此每个样本只有两个特征维度且就是x轴坐标与y轴坐标;Y为样本标签,因此它只是一个one-hot,用来标记每一个Point的类别。

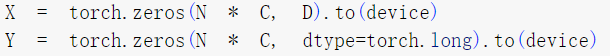
在课程2中给出了两个用Sequential表示的网络结构,第一个为单层感知机,包含一个输入层与输出层;第二个网络在输入层和输出层之间增加了一个Relu激活函数,网络的准确率大为提升(50% -> 95%)。我认为在此需要思考的问题是:为什么加入Relu激活函数以后会使网络的正确率大幅度提高呢?
这个问题我在之前的学习中也思考过,我在此给出我的答案:全连接神经网络是一个线性分类器,单层感知机无法解决分类问题中的异或问题,因为其决策边界是线性的,体现不出二维世界的坐标关系;激活函数的引入,可以将线性的值域扩展到非线性的域中,为决策边界带来非线性的因素,更能体现二维世界的坐标关系。
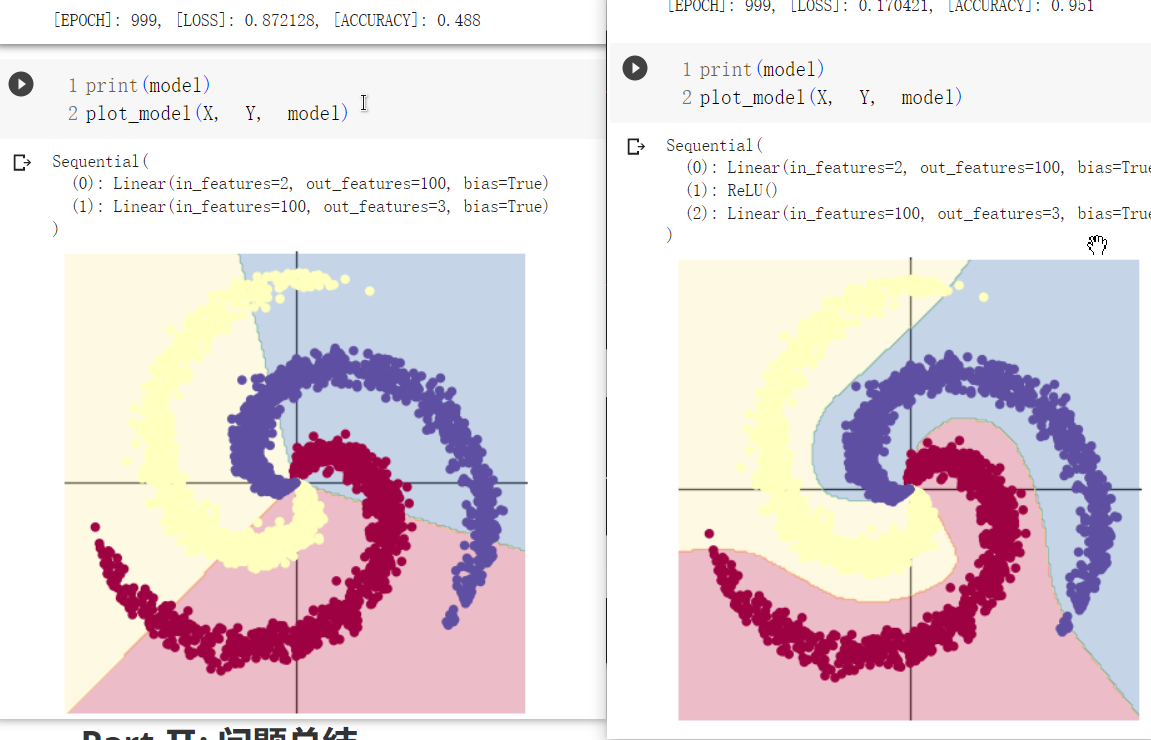
Part Ⅱ: 问题总结
思考下面的问题:1、AlexNet有哪些特点?为什么可以比LeNet取得更好的性能? 2、激活函数有哪些作用? 3、梯度消失现象是什么?4、神经网络是更宽好还是更深好?5、为什么要使用Softmax? 6、SGD 和 Adam 哪个更有效?如果还有其它问题,可以总结一下,写在博客里,下周一起讨论。
2.1 AlexNet & LeNet
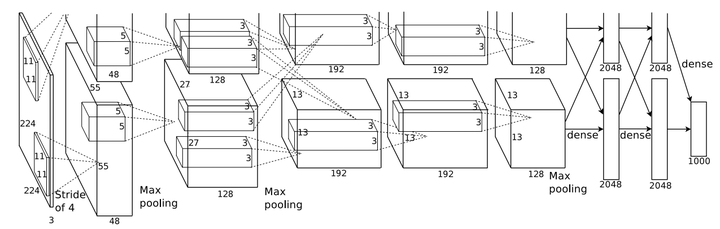
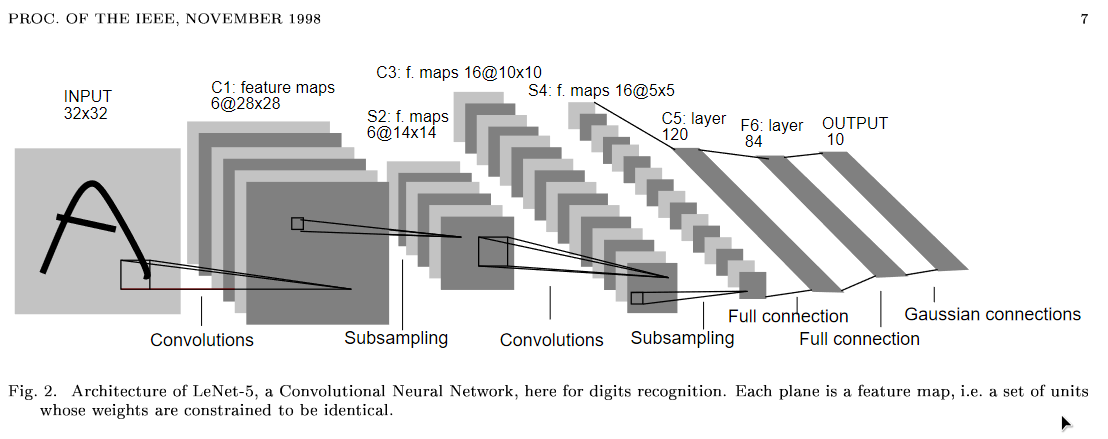
要说AlexNet有什么特点,我认为最大的便是其引入了LRN层;在《神经网络与深度学习》中,作者认为任何损害优化的方法都称为正则化,正则化有利于加强模型的泛化能力。
局部响应归一化(LRN)对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
AlexNet与LeNet相比,最明显的区别是前者引入了更多的卷积层,更多的卷积层意味着AlexNet能够学习到更多的参数,对模型的拟合能力有很大的提升。其次AlexNet的的池化层使用的是Max Pooling,而Lenet使用的是Average Pooling。
2.2 激活函数的作用
引用1.2中的思考:激活函数的引入,可以将线性的值域扩展到非线性的域中,为决策边界带来非线性的因素,更能体现二维世界的坐标关系。
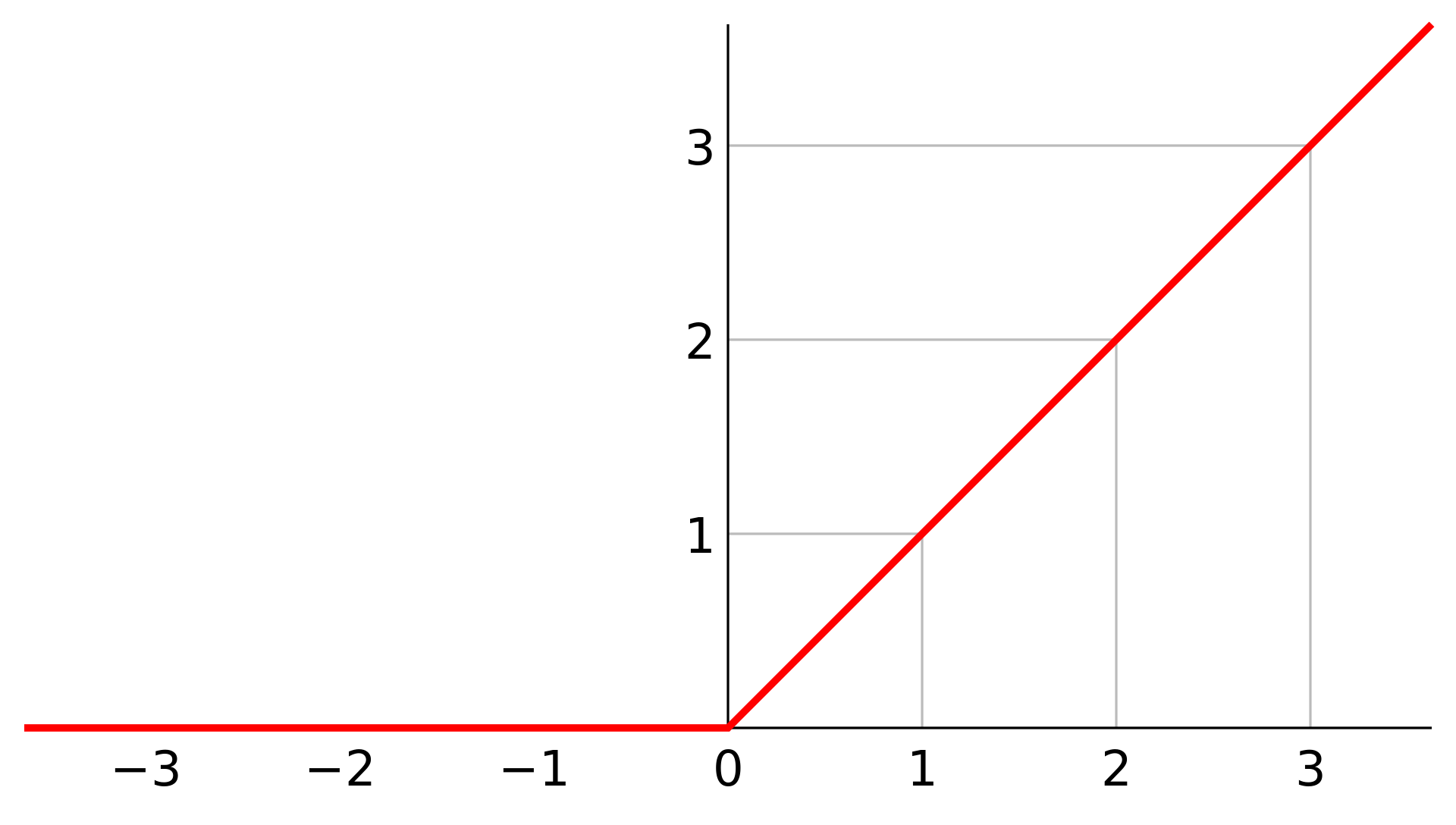
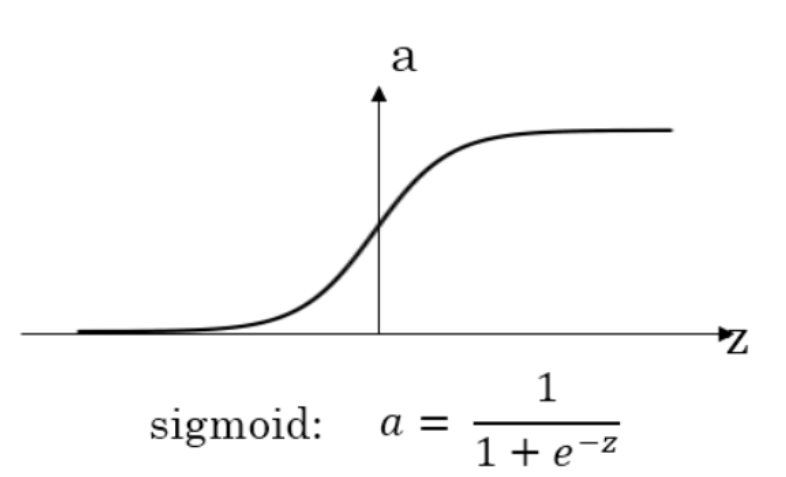
2.3 什么是梯度消失现象?
说到梯度消失就必须提到梯度下降,梯度下降是用于优化参数学习的一个方法;本质上就求目标函数的局部最小值,因此我们通常采用反向传播反复求其梯度找到局部最小值。
根据链式求导法则,如果我们整个链中某个环节的值过于小,则最终的梯度很容易消失;以sigmoid激活函数为例[8],如果网络中存在sigmoid函数,在求梯度时如果进入其梯度极小区,那么整个链式求导的值就会变得很小,甚至消失。
2.4 神经网络是更宽好还是更深好?
无数的工程经验告诉我们,神经网络更深更好,我也不明白为什么。
不过在此我提出一点个人观点:浅层的神经网络可以学习到很多低级特征(如猫的毛发,猫的头部轮廓),深层的神经网络可以学习到高级特征(如猫的头是由朝上的耳朵、长长的胡子和圆的头组成的);假如一个网络宽而浅,它自然能学习到巨量的低级特征,但是它并不知道那么多独特的特征组合在一起才是一个猫的头,它会认为只要样本具有这些特征,那就是猫。
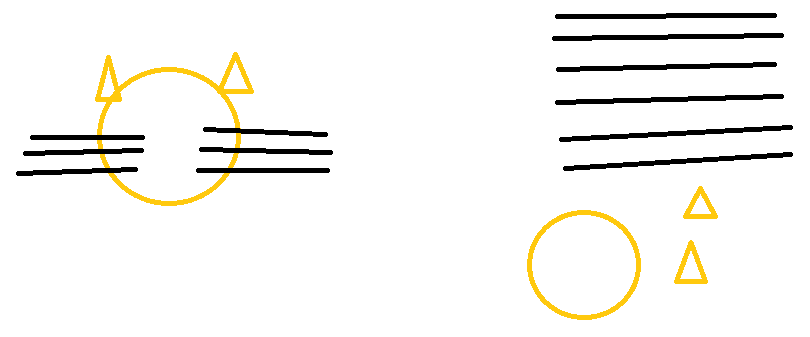
2.5 为什么要使用Softmax?
这题我会,Softmax将模型输出的每个类的权重进行计算,通过转化为一个概率分布,用于表示属于某类的概率大小。
2.6 SGD 和 Adam 哪个更有效?
这个问题太难为我了,如果我炼过很多炉子我肯定有个答案,但是我实践经验约等于没有。
所以我直接百度了,Adam = SGD + Momentum + AdaGrad/AdaDelta,这让Adam具有了SGD不具有的惯性下降与自适应学习率的能力,按理说Adam应该比SGD更加有效。
2.7 ……
Part Ⅲ: 进阶内容
im working on it.